stream processing

What is stream processing?
Stream processing is a data management technique that involves ingesting a continuous data stream to quickly analyze, filter, transform or enhance the data in real time. Once processed, the data is passed off to an application, data store or another stream processing engine.
Stream processing services and architectures are growing in popularity because they allow enterprises to combine data feed from various sources. Sources can include transactions, stock feeds, website analytics, connected devices, operational databases, weather reports and other commercial services.
The core ideas behind stream processing have been around for decades but are getting easier to implement with various open source tools and cloud services.
How does stream processing work?
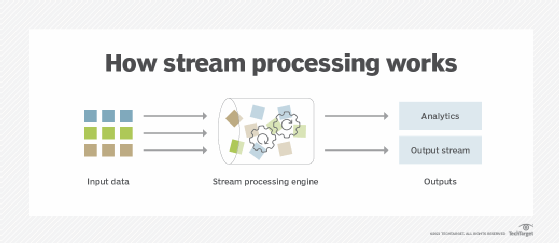
Stream processing architectures help simplify the data management tasks required to consume, process and publish the data securely and reliably. Stream processing starts by ingesting data from a publish-subscribe service, performs an action on it and then publishes the results back to the publish-subscribe service or another data store. These actions can include processes such as analyzing, filtering, transforming, combining or cleaning data.
Stream processing commonly connotes the notion of real-time analytics, which is a relative term. Real time could mean five minutes for a weather analytics app, millionths of a second for an algorithmic trading app or a billionth of a second for a physics researcher.
However, this notion of real time points to something important about how the stream processing engine packages up bunches of data for different applications. The stream processing engine organizes data events arriving in short batches and presents them to other applications as a continuous feed. This simplifies the logic for application developers combining and recombining data from various sources and from different time scales.
Why is stream processing needed?
Stream processing is needed to:
- Develop adaptive and responsive applications
- Help enterprises improve real-time business analytics
- Facilitate faster decisions
- Accelerate decision-making
- Improve decision-making with increased context
- Improve the user experience
- Create new applications that use a wider variety of data sources
How is stream processing used?
Modern stream processing tools are an evolution of various publish-subscribe frameworks that make it easier to process data in transit. Stream processing can reduce data transmission and storage costs by distributing processing across edge computing infrastructure.
Streaming data architectures can also make it easier to integrate data from multiple business applications or operational systems. For example, telecom service providers are using stream processing tools to combine data from numerous operations support systems. Healthcare providers use them to integrate applications that span multiple medical devices, sensors and electronic medical records systems. Stream processing also supports more responsive applications in anomaly detection, trend spotting and root cause analysis.
Common stream processing use cases include:
- Fraud detection
- Detecting anomalous events
- Tuning business application features
- Managing location data
- Personalizing customer experience
- Stock market trading
- Analyzing and responding to IT infrastructure events
- Digital experience monitoring
- Customer journey mapping
- Predictive analytics
What are the stream processing frameworks?
Spark, Flink and Kafka Streams are the most common open source stream processing frameworks. In addition, all the primary cloud services also have native services that simplify stream processing development on their respective platforms, such as Amazon Kinesis, Azure Stream Analytics and Google Cloud Dataflow.
These often go hand in hand with other publish-subscribe frameworks used for connecting applications and data stores. For example, Apache Kafka is a popular open source publish-subscribe framework that simplifies integrating data across multiple applications. Apache Kafka Streams is a stream processing library for creating applications that ingest data from Kafka, process it and then publish the results back to Kafka as a new data source for other applications to consume.
Other stream processing tools with novel capabilities are also growing in popularity. Samza is a distributed stream processing tool that allows users to build stateful applications. Apache Storm supports real-time computation capabilities like online machine learning, reinforcement learning and continuous computation. Delta Lake supports stream processing and batch processing using a common architecture.
What are the differences between stream and batch processing?
Stream processing and batch processing represent two different data management and application development paradigms. Batch processing originated in the days of legacy databases in which data management professionals would schedule batches of updates from a transactional database into a report or business process. Batch processing is suitable for regularly scheduled data processing tasks with well-defined boundaries. It is a good approach for pulling out transactional numbers from the sales database to generate a quarterly report or tallying employee hours to calculate monthly checks.
Stream processing allows developers to think about ingesting data as a continuous data stream. Technically speaking, the data still arrives in batches. Still, the stream processing engine manages the process of filtering out data updates and keeping track of what it has already uploaded into the feed. This frees up more time for data engineering and developer teams to code the analytics and application logic.
History of stream processing
Computer scientists have explored various frameworks for processing and analyzing data across multiple days since the dawn of computers. In the early days, this was called sensor fusion. Then, in the early 1990s, Stanford University professor David Luckham coined the term complex event processing (CEP). This helped fuel the development of service-oriented architectures (SOAs) and enterprise service busses (ESBs).
CEP's fundamental principles included abstractions for characterizing the synchronous timing of events, managing hierarchies of events and considering the causal aspects of events. The rise of cloud services and open source software led to more cost-effective approaches for managing event data streams, using publish-subscribe services built on Kafka.
This gave rise to stream processing frameworks that simplified the cost and complexity of correlating data streams into complex events. With the rise of the cloud, the industry is starting to move away from the terms SOA, ESB and CEP toward infrastructure built on microservices, publish-subscribe services and stream processing. Although the terms are different, the core idea inherent in these older technologies lives on.
Continue Reading About stream processing
Dig Deeper on Data integration
-
![]()
What to expect from Current 2024
By: Adrian Bridgwater
-
![]()
Green coding - Confluent: Sustainability through data streaming
By: Adrian Bridgwater
-
![]()
Confluent adds support for Apache Flink, unveils update
By: Eric Avidon
-
![]()
Confluent Current 2023: A journey around the data streaming universe
By: Adrian Bridgwater



