semantic technology

What is semantic technology?
Semantic technology is a set of methods and tools that provide advanced means for categorizing and processing data, as well as for discovering relationships within varied data sets. The techniques of semantic technology find use in diverse areas such as interactive intelligent agents, data lakes, data governance, and emerging cognitive applications.
As is the case with familiar linguistics that use semantics to disclose meanings in language, the purpose of semantic technology in computer systems is to uncover meaning within data. As human-machine interaction methods have advanced, the interest in semantic methods to uncover the meaning of voice and text communications have advanced as well.
Semantic technology vs. the semantic web
Parts of semantic technology have roots in early artificial intelligence and expert system research, but the tools that came into being as part of the Semantic Web movement in the early 2000's form the most immediate basis for modern semantic technology. These elements include the Resource Description Framework, or RDF, storage scheme, which uses triple style subject-predicate-object structures. It also includes query languages such as SPARQL. An added element is the Web Ontology Language, or OWL.
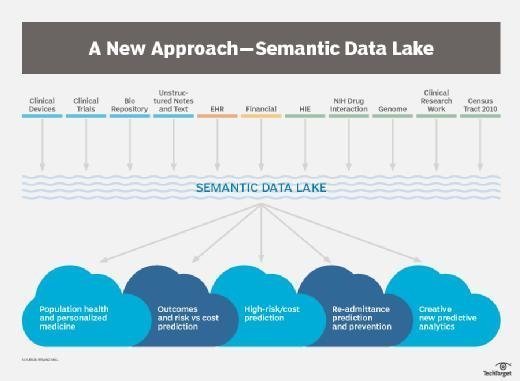
When combined with machine learning systems, network graph systems and graph databases, these semantic elements can be used to build semantic networks or graphs that can provide answers to users' queries in intelligent systems such as IBM Watson, Amazon Echo, Siri, Google Knowledge Graph or Microsoft Office Graph. Semantic approaches can also help support analytical queries across diverse data types in data lakes and operational database systems.
Although it gained initial attention, much of that due to the endorsement of web creator Tim Berners-Lee, the semantic web stalled. That was because the building blocks required to bring semantic technology to mainstream adoption took considerable time to develop.
But as the web and e-commerce continued to create large amounts of unstructured data, semantic technologists persisted in developing alternatives to incumbent relational data systems. They have worked to spur on semantic technologies that track relationships between diverse data elements in more subtle ways than are possible with traditional relational alternatives.







