Trifacta data prep tool helps blend disparate data sources
Handling diverse data sources usually consumes precious developer time. That led healthcare CRM company SymphonyRM to hand the data prep task to business analysts.
Today's advanced applications are meant to exploit machine learning and AI. But they are encountering some of the kinds of barriers that analytics applications have encountered for many years. Among the obstacles are disparate data sources.
This is because much time and labor is still needed to clean and prepare the data. That can hobble efforts to use the new machine learning libraries meant to change industries.
It's true in healthcare: a vital field in which hopes are high for AI success, but one in which disparate data sources can confuse matters.
One healthcare CRM software startup turned to self-service data prep tools from Trifacta Inc. to help guide healthcare professionals about the next best actions they can pursue with patients.
Data user, serve thyself
"In healthcare, the data is 'siloed,' messy," according to Joe Schmid, CTO at SymphonyRM, the startup working to apply machine learning to analyze diverse data and improve health professionals' interactions with patients.
To do that, Schmid has turned to tools that provide self-service data preparation capabilities to front-line data workers.
The SymphonyRM HealthOS system analyzes incoming patient data and applies advanced CRM techniques to inform clinical and post-acute care decisions.
Joe Schmid
The system employs Python machine learning libraries. It not only takes into account which remedies can be applied, but also prioritizes and tunes results according to the likelihood that the patient will follow specific medical advice, Schmid said.
Data ingested by HealthOS can take the form of clinical claims data, third-party demographic data, hospital databases and the still-ubiquitous Excel spreadsheet. The diversity of that data has been challenging.
Adding to the complexity of data preparation is that data sets arrive at varying frequencies, as they are created at varying rates.
And, even when disparate data sources bear kinship, the individualized formats supported by different organizations can vary slightly and, Schmid said, lead to "a pretty labor intensive process."
Code for ingestion
To get around an extract, transform and load process that relied on the work of many application developers, SymphonyRM employed Trifacta Wrangler data preparation software. The company did so, Schmid said, so that business analysts could take over more of the data preparation work that was consuming developers' time.
In healthcare, the data is 'siloed,' messy.
Joe SchmidCTO, SymphonyRM
Trifacta competes with Datameer, Paxata, Tibco Software, Unifi Software and others in a field of players focused on data preparation and self-service.
"Doing machine learning is important, but the quality of the data really matters," Schmid said. "Before we used Trifacta, we would bring in disparate data sources from different systems, and we had software engineers writing code that would ingest that data."
He said the Trifacta system allows data scientists to define schema and, as raw data comes into a data lake, it can be classified by business analysts to populate the target schema.
"Trifacta let us speed up the process to get the data. It's a visual tool. Now, we can shift that work from software engineers and data scientists to business analysts," he said.
Excel still prime tool
Although it may be surprising to some people, Excel still is a primary tool for data preparation. According to a Trifacta-sponsored survey of 295 data professionals released in May of this year, 37% of data analysts and 30% of IT professionals use it more than other tools to prepare data.
This did not surprise Schmid. He is aware of industry efforts underway to deal with diverse data via new interchange formats such as the Fast Healthcare Interoperability Resources standard. But there is no complete immediate replacement for Excel.
"There is talk about more modern APIs. But we don't have the luxury of working only with the new APIs," he said. Meanwhile, "Excel is something we see all the time."
Flexibility in ingesting data makes a difference, as does getting it out of the hands of high-cost developers and into the hands of the front-line people who know the data best, Schmid said.
Critical data preparation
It's not just about how to deal with long-established formats such as Excel. It's also about data preparation for formats yet to be encountered, he said.
"You really have to understand the breadth of the data coming in and not just what you have today," Schmid said.
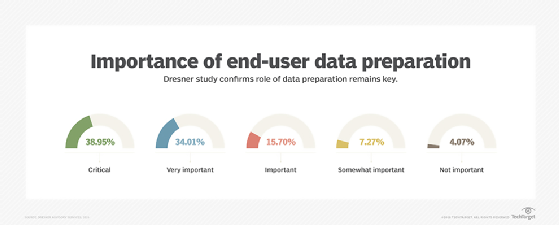
Industry research bears out Schmid's leanings. According to a recent survey from Dresner Advisory Services, self-service data preparation is increasingly important. That group's 2018 "End User Data Preparation" study found that 72% of all respondents mark end-user data preparation as either "critical" or "very important."
A 2018 'End-User Data Preparation' research survey by Dresner Advisory Services found that self-service data preparation was often a critical or key factor for respondents representing IT, BI centers of competency, executive management, R&D and various lines of business.
Still, self-service data preparation only happens after capable data engineers develop and test the data pipelines that feed analytics. What is key, according to Adam Wilson, CEO at Trifacta, is that teams are formed within organizations to intelligently distribute the work.
"There are millions of knowledge workers out there who have been told to be data-driven," Wilson said. They should not need to depend entirely on a small group of developers to be able to start work on data analytics, he added.
Data engineers are required to make sure that data analytics properly can scale up as more and more data arrives, Wilson said. Trifacta recently released RapidTarget and Automator capabilities that help data engineers create and maintain repeatable, scalable pipelines for data to serve analysts.


 Joe Schmid
Joe Schmid