data streaming

What is data streaming?
Data streaming is the continuous transfer of data from one or more sources at a steady, high speed for processing into specific outputs. Data streaming is not new, but its practical applications are a relatively recent development.
In the early years of the internet, connectivity wasn't always reliable and bandwidth limitations often prevented streaming data to arrive at its destination in an unbroken sequence. Developers created buffers to allow data streams to catch up but the resulting jitter caused such a poor user experience that most consumers preferred to download content rather than stream it.
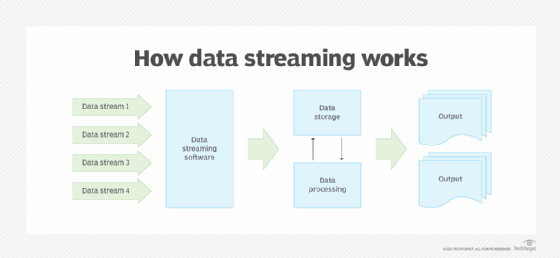
How data streaming works
The advent of broadband internet, cloud computing and the internet of things (IoT) have made data streaming easier. Today, businesses regularly use data from IoT devices and other streaming sources to make data-driven decisions and facilitate real-time analytics. Many companies have replaced traditional batch processing with streaming data architectures that can accommodate batch processing of high volumes of data.
In batch processing, new data elements are collected in a group and the entire group is processed at some future time. In contrast, a streaming data architecture or stream processor handles data in motion and an extract, load and transform (ELT) batch is treated as an event in a continuous stream of events. Streams of enterprise data are fed into data streaming software, which then routes the streams into storage and processing, and produces outputs, such as reports and analytics.
Examples of data streams
Data streaming use cases include the following:
- Weather data.
- Data from local or remote sensors.
- Transaction logs from financial systems.
- Data from health monitoring devices.
- Website activity logs.
Data comes in a steady, real-time stream, often with no beginning or end. Data may be acted upon immediately, or later, depending on user requirements. Streams are time stamped because they're often time-sensitive and lose value over time. The streamed data is also often unique and not likely repeatable; it originates from various sources and might have different formats and structures.
For example, various production sensors on a manufacturing production line capture different types of data and aggregate the data. Each sensor's data is then combined with data from the other sensors to provide a detailed view of the production system. A manufacturing resource planning system can use data from the various sensors to further refine how the production systems may be used, when they are scheduled, when maintenance is needed and other important metrics.
Pros and cons of data streaming
Data streaming comes with both advantages and drawbacks. Among the advantages are the following:
- Real-time business insights. Streamed data can be particularly useful for businesses that rely on real-time or near-real-time information for informed decision-making. Streaming lets businesses quickly identify trends and patterns and react fast to market changes.
- Multiple data flows. Data streaming is beneficial in situations where a continuous flow of data from multiple data pipelines must be processed into useful output. By bringing together data from various applications, streamed data can provide a variety of outputs based on user requirements.
- System visibility. Data streaming helps IT organizations identify issues quickly before they become problems.
- Scalability. Real-time data processing lets businesses handle large, complex data sets. This can be important for businesses that are growing rapidly and need to scale and optimize their data processing capabilities to keep up with demand.
The following are some of the drawbacks of data streaming:
- Data overload. With so much data being processed in real time, it can be difficult to identify the most relevant information. This can lead to businesses becoming overwhelmed by the data volume and unable to make meaningful decisions.
- Cost. Data streaming can be expensive, particularly if businesses must invest in new hardware and software to support it.
- Data loss or corruption. With traditional data processing methods, businesses may be able to recover lost data from backups or other sources. However, with data streaming, there's a risk that data may be lost or corrupted in real time, making it impossible to recover.
- Overhead. Data streaming requires storage and processing elements, such as a data warehouse or data lake, to prepare data for later use. The added overhead associated with data streaming must be analyzed in terms of its return on investment.
Data streaming and big data
To benefit from data streaming at the enterprise level, businesses with streaming architectures require powerful data analytics tools for ingesting and processing information. Popular enterprise tools for working with data streams include the following:
Amazon Kinesis Data Firehose. This real-time big data processing tool can handle hundreds of terabytes of streaming data per hour from data sources such as operating logs, financial transactions and social media feeds.
Apache Flink. This open source distributed data processing platform is used in big data applications, primarily for analysis of data stored in Hadoop clusters. Flink handles both batch and stream processing jobs, with data streaming the default implementation and batch jobs running as special-case versions of streaming applications.
Minimum recommended download speeds for viewing streaming data
To get a reasonable estimate of bandwidth -- also called throughput -- data engineers suggest the use of at least three test apps or sites, such as Fast.com, and that each test be conducted several times to ensure an accurate read.
Various streaming platforms require different download speeds. Some of the more popular consumer services require the following speeds:
- Amazon Prime Video. 3.5 megabits per second (Mbps) for high definition (HD) videos and 15 Mbps for 4K streaming.
- DirecTV Stream. 25 Mbps for households that maintain internet use on multiple devices.
- Hulu. 3-25 Mbps depending on the video quality, with 25 Mbps required for Ultra HD quality.
- Netflix. 3-25 Mbps depending on the video quality, with 25 Mbps recommended for 4K Ultra HD streaming.
- PlayStation Vue. At least 20 Mbps download speed to ensure a consistent stream.
- YouTube TV. 13 Mbps to reliably stream HD video.
Required speeds vary depending on the number of devices connected to the network and the type of media being played. For 4K content and online gaming, higher megabits per second speeds are generally required for the best customer experience.
Find out how streaming analytics can provide insight and value to your organization.







