
Sergey Galushko - Fotolia
Should you host your data lake in the cloud?
On premises or in the cloud: What's the better place for your data lake? Here are some things to consider before deciding where to deploy a big data environment.

Large companies have many applications. One I recently worked with had over 600 documented IT applications, just one of which was its ERP system. To get any sense of business performance across the enterprise, you need to aggregate data from those applications, resolving inconsistencies in data definitions and classifications of products, customers, suppliers, etc.
This non-trivial task, which requires dealing with data quality problems and other thorny issues, often results in a data warehouse. Keeping the data warehouse up to date amid corporate restructuring, acquisitions and other business changes is a major challenge for data management teams, but it's what companies -- with mixed degrees of success -- have primarily relied on to give them a unified view of their business.
Until recently, at least, when the concept of the data lake emerged to offer a big data alternative to the traditional data warehouse. Now, there's a growing push among IT vendors to support deployments of a data lake in the cloud. But there are issues to consider before deciding to put your data lake there.
Welcome to the data lake
First, what exactly is a data lake? The advent of big data in volumes too large and diverse for conventional databases to handle complicated things technically and economically for IT managers. Big data comes from smart meters, sensors, web logs, telephone masts, social media and many other sources, often in unstructured or semistructured forms. A modern airplane generates up to 5 TB of data per flight, while an autonomous car spews out 40 TB per day. Relational databases weren't designed for such high volumes and varied data sets, and costs can quickly rise when you try to scale them up to handle big data workloads.
A cheaper and more suitable option appeared in the form of Hadoop, an open source distributed processing framework with a built-in file system. Hadoop lets users store and manage very large volumes of data on clusters of commodity hardware, and it was pressed into service to deal with the big data companies were generating, along with supporting technologies like Spark and HBase. Big data systems grew into full-fledged data lakes. And more deployment alternatives became available. For example, another option for a data lake in the cloud is to bypass Hadoop and run a processing engine like Spark against data in a cloud object storage service.
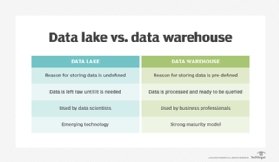
Before beginning a data lake deployment, it's important to understand that the data in one often isn't processed or summarized upfront like what's found in a data warehouse is. The term data lake typically describes a store of raw data that can be prepared for specific analytics uses as needed. To contrast data lakes and data warehouses, think of the difference between the water of a real lake and a bottle of Evian, which has been filtered and packaged for easy consumption.
Initially, most data lakes were deployed inside the corporate firewall. However, it takes a lot of resources to maintain a growing data lake and add and manage more servers as the data pours in. Just as cloud vendors have stepped into other parts of the IT market that companies used to handle in-house, it isn't surprising that the same has happened with data lakes.
Data lakes in the cloud
Managing a data lake in your own data center -- also including the need to deal with backups, security, hardware failures and other administrative tasks -- is a major effort. That's why cloud deployments and managed services have become a more prevalent alternative to on-premises Hadoop clusters for data lakes.
AWS, Microsoft and Google are among the vendors that offer data lakes in the cloud. But there are some important data lake management issues to consider before handing over your environment and data to a cloud service provider.
On the plus side, the administration of the environment is someone else's problem, and you can scale it up or down as needed without having to invest in new hardware. On the other hand, you need to consider whether you trust the cloud provider to handle the security of your data, much of which may be highly sensitive, and whether you trust its ability to operate the service and keep it running.
Although the majority of providers are getting more reliable, even in 2019 there were major cloud service outages affecting Microsoft Azure (on Jan. 29) and Google Cloud (on June 2). But is your internal data center any less likely to run into an issue with outages? That's a question your organization should ask itself.
In many cases, the decision on whether to run a data lake in the cloud or in-house comes down to whether you have faith in a third-party provider to maintain your data safely and securely. In the early days of the cloud, corporations often were nervous about having their data outside the corporate firewall. Gradually, though, the increased flexibility and potential economic benefits of moving data platforms to the cloud have outweighed those concerns for many companies.
These days, more and more applications are moving to the cloud, including data lakes, with worldwide spending on cloud computing in 2019 forecast to grow almost 24% over the 2018 level, according to an IDC report. As early as 2017, 90% of companies were using some type of cloud service, according to a survey conducted that year by 451 Research.
Making the data in a data lake useful
After deciding if they should host a data lake in the cloud or in-house, the other large hurdle companies face is how to effectively use the data filling up their data lakes at an increasing pace.
Being a data analyst confronted by such a high volume of data is like trying to drink from a fire hose. You need to classify the data being stored in the data lake, tag its data sets with metadata that makes the information identifiable later and start to map how this data relates to your other corporate data. Adding meaningful metadata to the raw data is especially important. If you don't do that, your data lake will be more of a data swamp.
Companies often set up their data lakes alongside traditional data warehouses, with data pumped out of the lake into the warehouse as needed for analytics applications. Before deciding whether to go with a cloud service for your data lake, you also need to consider whether that service is a good complement to your data warehouse.
For example, if your data lake takes in social media feeds with customer comments about your brand, can you relate that sentiment data to your customer data? You might want to pay a lot more attention to someone who's complaining about product or customer service problems if they're a valued customer in your corporate loyalty scheme, but first you need to able to make that connection between the data lake and the data warehouse.
Wrangling the raw data lake and combining it with mainstream corporate data presents many business opportunities, but it's also a major challenge for hard-pressed data management staff. And that applies whether it's deployed in the cloud or on premises.







