
Torbz - Fotolia
SQL vs. NoSQL vs. NewSQL: How do they compare?
Choosing which database management system depends on an organization's needs. Review the differences among SQL, NoSQL and NewSQL and how to select the right database system.

The landscape for database management systems (DBMSes) continues to evolve to adapt to changing requirements for transaction processing, data access and big data applications. One distinguishing characteristic of modern DBMS offerings is in their SQL capabilities. At a high level, it is possible to categorize most modern DBMS products into one of the following designations:
- SQL
- NoSQL
- NewSQL
But these terms can contain multiple layers of meaning. To further complicate matters, they are not mutually exclusive.
What are SQL and relational database systems?
At a high-level SQL, or Structured Query Language, is the standard query language for interacting with a relational database management system (RDBMS). Indeed, every RDBMS -- and many nonrelational DBMS products -- supports SQL as the method for accessing data.
Although relational and SQL are used somewhat analogously, there are differences. While the differences are more nuanced, a traditional SQL database system can be thought of as being based on the relational model. The relational model relies on set theory and relations to describe data in the database. From an external viewpoint, this means data is viewed as tables of rows and columns using a fixed schema, meaning each row has the same columns defined using the same data types as every other row in a table.
Each table row has a key that uniquely identifies the row. For example, the Product table key may be Product ID. Relationships between tables are defined by the values of columns. For example, the Order table is related to the Product table by means of the Product ID column, which must exist in both tables.
Furthermore, SQL database systems are typified by their support of ACID (atomicity, consistency, isolation and durability) support for transactions. A DBMS with ACID support generally means data consistency is strictly maintained as multiple processes access and modify the same data.

Advantages and disadvantages of SQL database systems
Advantages of using SQL database systems include:
- SQL database systems are pervasive and fit well for general-purpose data storage, management and access requirements.
- All data access is accomplished using a single, standardized language.
- SQL is portable across different DBMS products with minimal changes.
- SQL database systems have a 40-year history of success, and, as such, there are many users of SQL database systems, making it is easier to find skilled professionals to develop and administer these databases.
Disadvantages of using SQL database systems include:
- Relational databases need a fixed schema, as they sometimes don't work with modern development. RDBMSes are not well suited to work with niche areas in comparison to NoSQL database systems.
- Because of the ACID consistency model, SQL databases can't scale horizontally, but they can scale vertically by increasing CPU and memory.
Examples of SQL database systems
Many of the most popular database systems in use today are based on relational and SQL, including:
- Oracle Database
- Microsoft SQL Server
- MySQL
- IBM Db2
- PostgreSQL
What is NoSQL?
As data volume has grown over the past few decades, SQL databases have struggled with particular use cases driven by big data requirements. NoSQL (Not Only SQL) database systems grew in popularity to support use cases, such as:
- Profile management
- Content management
- Mobile application
- Real-time usage of structured and unstructured data
- Social media management
NoSQL suggests nonrelational, distributed, flexible and scalable. Many NoSQL database systems are also open source. Additionally, some common features of NoSQL DBMSes include data clustering, lack of a fixed schema, replication support and eventual consistency, which is in opposition to the usual ACID transaction capability of SQL database systems.
An eventually consistent approach tolerates inconsistent data across nodes for a period of time. However, as the name implies, data integrity is eventually enforced across all the nodes.
Another big difference between NoSQL and relational/SQL is that NoSQL systems do not require SQL for accessing data. However, many NoSQL databases have added support for SQL.
Whereas SQL database systems require a rigidly defined schema, most NoSQL databases implement flexible schemas, wherein each instance of data (e.g., table row) need not contain the same data elements and definition. When data structures can evolve over time, a NoSQL database system can be more practical than a SQL/relational database system.
There are no hard-and-fast rules as to how NoSQL databases store data. There are actually multiple types of DBMS platforms categorized as NoSQL, which can be viewed as an overarching descriptor for four different types of database systems:
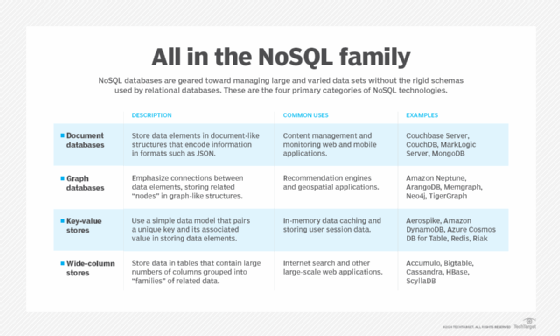
- Key-value databases store pairs of unique keys and associated values.
- Document databases store data in document-like structures encoded in formats such as JSON and XML.
- Wide-column databases store data in tables that contain large numbers of columns (in a flexible schema).
- Graph databases store data in graph form to highlight the connections between different data elements.
Each type of NoSQL DBMS is best suited to particular use cases and has individual pros and cons to consider.
Advantages and disadvantages of NoSQL database systems
NoSQL database systems have the following advantages:
- NoSQL database systems simplify some types of application development, such as interactive real-time web applications using a representational state transfer application programming interfaceand web services.
- They support flexibility for data that has not been normalized, which requires a flexible data model or has different properties for different data entities.
- NoSQL database systems deliver scalability for larger data sets, which are common in analytics and artificial intelligence applications.
- NoSQL is better suited for cloud, mobile, social media and big data requirements.
- They are easier to use than general-purpose SQL databases for the use cases for which they are designed.
Disadvantages of NoSQL database systems include:
- Each NoSQL database has its own syntax for querying and managing data. This contrasts with SQL, which is standard for all SQL database systems.
- Lack of a rigid database schema and constraints removes the data integrity safeguards that are built into SQL database systems.
- A schema with some sort of structure is required in order to use the data. With NoSQL, this must be performed by the application developer instead of the database administrator.
- Eventual consistency is typically acceptable only for fault-tolerant applications, as it does not provide the same level of data consistency as the ACID support built into SQL databases.
- Because NoSQL is newer, there are no comprehensive industry standards as with relational and SQL DBMS offerings. Additionally, it can be more difficult to find skilled NoSQL professionals.
Examples of NoSQL database systems
There is a plethora of popular NoSQL database systems used for production workloads today, including:
- MongoDB, a document database
- Redis, a key/value database
- Cassandra, a wide-column database
- Neo4j, a graph database
What is NewSQL?
Yet another type of database system, NewSQL, is a class of modern relational/SQL DBMS that provides the same scalable performance of NoSQL systems for online workloads but also provides ACID so as to not sacrifice data consistency. The term was first used by 451 Research in a 2011 research paper discussing the rise of new database systems as challengers to established vendors.
Basically, a NewSQL DBMS is engineered as a relational, SQL database system with a distributed, fault-tolerant architecture. Other typical features of NewSQL offerings include in-memory capability and clustered database services with the ability to be deployed in the cloud. Many NewSQL DBMS packages have fewer features and components and a smaller footprint than legacy relational offerings, making them easier to support and understand.
The general use case for NewSQL is to support enterprise systems that must process large amounts of data (big data) while maintaining transactional consistency and are, therefore, not practical for the eventual consistency of NoSQL database systems.
There are several different approaches taken by NewSQL database systems to achieve higher scalability with ACID consistency. Many NewSQL database systems are built on new, modern architectures that were not conceivable when the earliest SQL database systems were developed in the late 1970s. For example, many NewSQL offerings deploy a cluster of shared-nothing nodes, each managing a subset of the data with distributed concurrency control and query processing to balance the workload.
Another approach taken by NewSQL vendors is to transparently shard data across multiple nodes using a consensus algorithm. And most NewSQL database systems deploy improved SQL engines for data storage and optimization.
Advantages and disadvantages of NewSQL
Advantages of NewSQL database systems include:
- NewSQL works well for applications having many short transactions that access a small amount of indexed data and execute repetitively.
- NewSQL uses SQL, the most common data access language and, therefore, provides familiarity for developers and programmers.
- NewSQL supports ACID transaction consistency, thereby providing better data integrity than most NoSQL alternatives.
- NewSQL can reduce complexity for applications that do not require all the bells and whistles of a traditional SQL DBMS.
Disadvantages of NewSQL database systems include:
- NewSQL has fewer features than traditional SQL and, therefore, NewSQL is not as capable for general purpose implementation.
- The lack of tools to support development and administration as compared to traditional SQL database systems.
- There are fewer skilled professionals available due to NewSQL's newer technology.
Examples of NewSQL database systems
An increasing number of NewSQL DBMS offerings are being implemented for production workloads, including:
- CockroachDB
- VoltDB
- NuoDB
- SingleStore
- Clustrix
How to choose among SQL vs. NoSQL vs. NewSQL
After reviewing the basics of each type of database system, the question of which DBMS to choose may remain.
It makes sense to use SQL database systems as the baseline for most general-purpose requirements. There is a reason the SQL DBMS is as popular and entrenched as it is: It works very well for many of the most common use cases.
For applications with extreme availability and scalability needs or with unknown or changing data requirements where a flexible schema would be useful, consider a NoSQL database system. But take heed of the potential for data consistency issues and realize that NoSQL is a term that describes four different types of database systems, each with different use cases and architectures.
Finally, consider a NewSQL database system for applications that have expanded past the scalability capability of traditional SQL. Using NewSQL enables improved scalability with the strong transaction consistency of ACID, while still supporting data access using the familiar SQL.







