
Getty Images
NoSQL database types explained: Column-oriented databases
Learn about the uses of column-oriented databases and the large data model, data warehouses and high-performance querying benefits the NoSQL database brings to organizations.

In the effort to meet the increasing demand for data storage and accommodate data variety in the most efficient way, there is a growing tendency to opt for nonstandard database types. For years relational databases have been the norm. However, as requirements change and storage prices drop, people often choose to go with non-relational databases.
Columnar databases fit this description. These are NoSQL databases built for highly analytical, complex-query tasks. Unlike relational databases, columnar databases store their data by columns, rather than by rows. These columns are gathered to form subgroups.
The keys and the column names of this type of database are not fixed. Columns within the same column family, or cluster of columns, can have a different number of rows and can accommodate different types of data and names.
These databases are most often utilized when there is a need for a large data model. They are very useful for data warehouses, or when there is a need for high performance or handling intensive querying.
How column-oriented databases work
Relational databases have a set schema and they function as tables of rows and columns. Wide-column databases have a similar, but different schema. They also have rows and columns. However, they are not fixed within a table, but have a dynamic schema. Each column is stored separately. If there are similar (related) columns, they are joined into column families and then the column families are stored separately from other column families.
The row key is the first column in each column family, and it serves as an identifier of a row. Furthermore, each column after that has a column key (name). It identifies columns within rows and thus enables the querying of the columns. The value and the timestamp come after the column key, leaving a trace of when the data was entered or modified.
The number of columns pertaining to each row, or their name, can vary. In other words, not every column of a column family, and thus a database, has the same number of rows. In fact, even though they might share their name, each column is contained within one row and does not run across all rows.
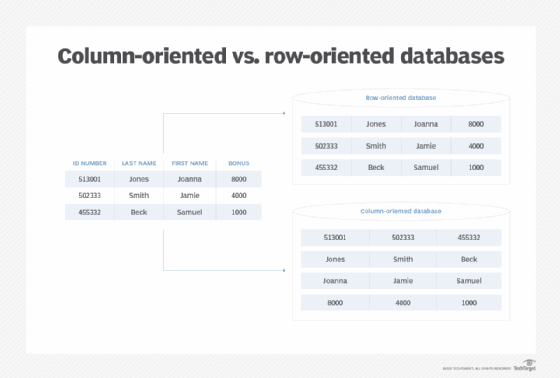
Those who have encountered relational databases know that each column of a relational database has the same number of rows, but it happens that some of the fields have a null value, or they appear to be empty. With wide-column databases, rather than being empty, these rows simply do not exist for a particular column.
The column families are located in a keyspace. Each keyspace holds an entire NoSQL data store and it has a similar role or importance that a schema has for a relational database. However, as NoSQL datastores have no set structure, keyspaces represent a schemaless database containing the design of a data store and its own set of attributes.
One of the most popular columnar databases available is MariaDB. It was created as a fork of MySQL intended to be robust and scalable, handle many different purposes and a large volume of queries. Apache Cassandra is another example of a columnar database handling heavy data loads across numerous servers, making the data highly available. Some of the other names on this list include Apache HBase, Hypertable and Druid specially designed for analytics. These databases support certain features of platforms such as Outbrain, Spotify and Facebook.
Column family types
- Standard column family. This column family type is similar to a table; it contains a key-value pair where the key is the row key, and the values are stored in columns using their names as their identifiers.
- Super column family. A super column represents an array of columns. Each super column has a name and a value mapping the super column out to several different columns. Related super columns are joined under a single row into super column families. Compared to a relational database, this is like a view of several different tables within a database. Imagine you had the view of the columns and values available for a single row -- that is a single identifier across many different tables -- and were able to store them all in one place: That is the super column family.
Advantages of column-oriented databases
- Scalability. This is a major advantage and one of the main reasons this type of database is used to store big data. With the ability to be spread over hundreds of different machines depending on the scale of the database, it supports massively parallel processing. This means it can employ many processors to work on the same set of computations simultaneously.
- Compression. Not only are they infinitely scalable, but they are also good at compressing data and thus saving storage.
- Very responsive. The load time is minimal, and queries are performed fast, which is expected given that they are designed to hold big data and be practical for analytics.
Disadvantages of column-oriented databases
- Online transactional processing. These databases are not very efficient with online transactional processing as much as they are for online analytical processing. This means they are not very good with updating transactions but are designed to analyze them. This is why they can be found holding data required for business analysis with a relational database storing data in the back end.
- Incremental data loading. As mentioned above, typically column-oriented databases are used for analysis and are quick to retrieve data, even when processing complex queries, as it is kept close together in columns. While incremental data loads are not impossible, columnar databases do not perform them in the most efficient way. The columns first need to be scanned to identify the right rows and scanned further to locate the modified data which requires overwriting.
- Row-specific queries. Like the potential downfalls mentioned above, it all boils down to the same issue, which is using the right type of database for the right purposes. With row-specific queries, you are introducing an extra step of scanning the columns to identify the rows and then locating the data to retrieve. It takes more time to get to individual records scattered in multiple columns, rather than accessing grouped records in a single column. Frequent row-specific queries might cause performance issues by slowing down a column-oriented database, which is particularly designed to help you get to required pieces of information quickly, thus defeating its purpose.
NoSQL databases are mostly designed to fit specific purposes and are not expected to work as a general type of storage. Wide-column databases are column-oriented rather than row-oriented and are intended to store and query big data. There are many different databases available within the type and it is worth exploring their features while on a hunt for the most suitable data storage solution.






