NoSQL (Not Only SQL database)
What are NoSQL databases?
NoSQL is an approach to database management that can accommodate a wide variety of data models, including key-value, document, columnar and graph formats. A NoSQL database generally means that it is non-relational, distributed, flexible and scalable. Additional common NoSQL database features include the lack of a database schema, data clustering, replication support and eventual consistency, as opposed to the typical ACID (atomicity, consistency, isolation and durability) transaction consistency of relational and SQL databases. Many NoSQL database systems are also open source.
The term NoSQL originally could be taken at its word -- that is, SQL was not used as the API to access data. However, the ubiquity and usefulness of SQL caused many NoSQL databases to add support for SQL. Today it is commonly accepted that NoSQL stands for "Not Only SQL."
What are the types of NoSQL databases?
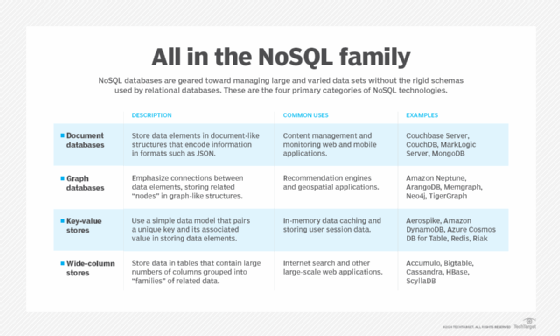
There are four popular types of NoSQL database systems. Each uses a different type of data model, resulting in significant differences between each NoSQL type.
Document databases. Also called document stores, these databases store semi-structured data and descriptions of that data in document format. They enable developers to create and update programs without needing to reference master schema. Use of document databases has increased along with the use of JavaScript and the JavaScript Object Notation (JSON), a data interchange format that has gained wide currency among web application developers. Document databases are used for content management and mobile application data handling, such as blogging platforms, web analytics and e-commerce applications. Couchbase Server, CouchDB, MarkLogic and MongoDB are examples of document databases.
Graph databases. Graph data stores organize data as nodes, which are similar to rows in a relational database, and edges, which represent connections between nodes. Because the graph system stores the relationship between nodes, it can support richer representations of data relationships. Also, unlike relational models that rely on strict schemas, the graph data model can evolve over time and use. Graph databases are applied in systems that must map relationships, such as social media platforms, reservation systems or customer relationship management. Examples of graph databases include AllegroGraph, IBM Graph and Neo4j.
Key-value stores. Also known as key-value databases, these systems implement a simple data model that pairs a unique key with an associated value. Because this model is simple, it can be used to develop highly scalable and performant applications. Key-value databases are ideal for session management and caching in web applications, such as those needed when managing shopping cart details for online buyers or for managing session details for multiplayer gaming. Implementations differ in the way they are oriented to work with RAM, solid-state drives or disk drives. Examples of popular key-value databases include Aerospike, DynamoDB, Redis and Riak.
Wide-column stores. These databases use familiar tables, columns and rows like relational database tables, but column names and formatting can differ from row to row in a single table. Each column is also stored separately on disk. As opposed to traditional row-orientated storage, a wide-column store is optimal when querying data by columns. Typical applications where wide-column stores can excel include recommendation engines, catalogs, fraud detection and event-logging. Accumulo, Amazon SimpleDB, Cassandra, HBase and Hypertable are examples of wide-column stores.
These basic NoSQL database classifications are only guides. Over time, vendors have mixed and matched elements from different NoSQL database families to achieve more generally useful systems. That evolution is seen, for example, in MarkLogic, which added a graph store and other elements to its original document databases. Couchbase Server supports both key-value and document approaches. Cassandra has combined key-value elements with a wide-column store and a graph database. Sometimes NoSQL elements are mixed with SQL elements, creating a variety of databases that are referred to as multimodel databases.
Advantages of NoSQL
There are several advantages to using NoSQL databases, including:
- NoSQL databases simplify application development, particularly for interactive real-time web applications, such as those using a REST API and web services.
- These databases provide flexibility for data that has not been normalized, which requires a flexible data model, or has different properties for different data entities.
- They offer scalability for larger data sets, which are common in analytics and artificial intelligence (AI) applications.
- NoSQL databases are better suited for cloud, mobile, social media and big data requirements.
- They are designed for specific use cases and are easier to use than general-purpose relational or SQL databases for those types of applications.
Disadvantages of NoSQL
The disadvantages of using a NoSQL database include the following:
- Each NoSQL database has its own syntax for querying and managing data. This is in contrast to SQL, which is the lingua franca for relational and SQL database systems.
- Lack of a rigid database schema and constraints removes the data integrity safeguards that are built into relational and SQL database systems.
- A schema with some sort of structure is required in order to use the data. With NoSQL, this must be performed by the application developer instead of the database administrator.
- Because most NoSQL databases use the eventual consistency model, they do not provide the same level of data consistency as SQL databases. At times the data will not be consistent, which means they are not well-suited for transactions that require immediate integrity, such as banking and ATM transactions.
- Because NoSQL databases are newer, there are no comprehensive industry standards as with relational and SQL DBMS offerings.
NoSQL vs. SQL: What's the difference?
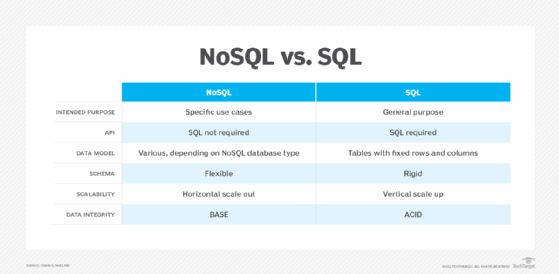
At a high level, SQL databases are general purpose, whereas NoSQL databases are engineered for specific use cases. The primary differences between NoSQL and SQL can be summed up in the following five categories: API, data model, schema requirement, scalability and data integrity. Each deploys a different approach to these aspects of data storage and retrieval.
API. For NoSQL, SQL is not required as an API to the data in the database, although many NoSQL databases offer a SQL-like query language. For SQL databases, SQL is typically the only, or predominant, interface to the data.
Data model. With NoSQL database systems, data is not modeled as tables with fixed rows and columns, as with a SQL DBMS. Instead, depending on the NoSQL database, data can be modeled as JSON documents, graphs with nodes and edges, or key-value pairs. Wide-column stores use the table and row concept, but columns can be dynamic from row to row within a table.
Schema. The schema for a NoSQL database is flexible, meaning there is no fixed structure to the data, data types and lengths for data elements. Data can be stored in a free-form, or schemaless manner. This approach offers programmers a higher degree of flexibility, which can ease development efforts.
With SQL, databases the schema is fixed, with rigid data types and lengths for each column, and every row must match the defined column layout and structure. For example, if a column is defined as an integer, only integer data can be stored in the column and any attempt to do otherwise is rejected by the DBMS. This approach delivers better data quality because the DBMS enforces rules as data is added.
Scalability. NoSQL databases usually implement horizontal scaling, also known as scaling out. Scaling out involves adding more hardware to a system, usually in the form of new commodity servers. Horizontal partitioning using sharding to break up large databases into smaller pieces spread across multiple servers is frequently used in NoSQL systems.
The SQL approach typically is vertical scaling, also referred to as scaling up. With vertical scaling, additional resources are added, such as a more powerful CPU or additional memory, to handle additional workload or to improve performance.
Data integrity. NoSQL and SQL databases use different approaches to protect the integrity of data as it is created, read, updated and deleted by applications and users.
Most NoSQL database systems manage data integrity with an approach known as BASE (Basically Available, Soft State with Eventual Consistency). Using BASE, data may be inconsistent for a period of time, but database replication eventually updates all copies of the data to be consistent. Some applications can tolerate this type of inconsistent data, whereas others cannot.
The approach used by SQL databases is the aforementioned ACID. Each of its four qualities -- atomicity, consistency, isolation and durability -- contribute to the ability of a transaction to ensure data integrity. Using ACID, each transaction -- when executed alone, in a consistent database state -- will either complete, producing correct results, or terminate, with no effect. In either case, the resulting condition of the database always will be a consistent state.
Evolution of NoSQL
SQL and relational database systems are pervasive because they deliver a good, general purpose mechanism for supporting most data management requirements. They are designed to be reliable, accurate and useful for planned applications and ad hoc queries. Nevertheless, some SQL and relational requirements -- for example, rigid schema and strict ACID -- can make them less suitable for applications that require flexible data and high speed.
As a reaction, NoSQL database systems arose to address these needs, many developed by companies such as Amazon with its DynamoDB, Facebook and its Apache Cassandra, and Google with its BigTable database to address their specific needs. Another early influential NoSQL database system is Berkeley DB, developed at the University of California, Berkeley, beginning in the 1990s, Berkeley DB was widely described as an embedded database that closely supported specific applications' storage needs. This open source software provided a simple key-value store. Berkeley DB was commercially released by Sleepycat Software in 1999. The company was later acquired by Oracle in 2006. Oracle has continued to support open source Berkeley DB.
The NoSQL term can be applied to some databases that predated the relational database management system (RDBMS), but it more commonly refers to the databases built in the early 2000s for the purpose of large-scale database clustering in cloud and web applications.






