Subsurface event reveals what lies below the cloud data lake
Users at the Dremio-sponsored Subsurface virtual conference detail data lake efforts and trends, including the emerging Apache Iceberg project, originally created by Netflix.
There is much interest in cloud data lakes, an evolving technology that can enable organizations to better manage and analyze data.
At the Subsurface virtual conference on July 30, sponsored by data lake engine vendor Dremio, organizations including Netflix and Exelon Utilities, outlined the technologies and approaches they are using to get the most out of the data lake architecture.
The basic promise of the modern cloud data lake is that it can separate the compute from storage, as well as help to prevent the risk of lock-in from any one vendor's monolithic data warehouse stack.
In the opening keynote, Dremio CEO Billy Bosworth said that, while there is a lot of hype and interest in data lakes, the purpose of the conference was to look below the surface -- hence the conference's name.
"What's really important in this model is that the data itself gets unlocked and is free to be accessed by many different technologies, which means you can choose best of breed," Bosworth said. "No longer are you forced into one solution that may do one thing really well, but the rest is kind of average or subpar."
Why Netflix created Apache Iceberg to enable a new data lake model
In a keynote, Daniel Weeks, engineering manager for Big Data Compute at Netflix, talked about how the streaming media vendor has rethought its approach to data in recent years.
"Netflix is actually a very data-driven company," Weeks said. "We use data to influence decisions around the business, around the product content -- increasingly, studio and productions -- as well as many internal efforts, including A/B testing experimentation, as well as the actual infrastructure that supports the platform."
What's really important in this model is that the data itself gets unlocked and is free to be accessed by many different technologies, which means you can choose best of breed.
Billy BosworthCEO, Dremio
Netflix has much of its data in Amazon Simple Storage Service (S3) and had taken different steps over the years to enable data analytics and management on top. In 2018, Netflix started an internal effort, known as Iceberg, to try to build a new overlay to create structure out of the S3 data. The streaming media giant contributed Iceberg to the open source Apache Software Foundation in 2019, where it is under active development.
"Iceberg is actually an open table format for huge analytic data sets," Weeks said. "It's an open community standard with a specification to ensure compatibility across languages and implementations."
Iceberg is still in its early days, but beyond Netflix, it is already finding adoption at other well-known brands including Apple and Expedia.
Not all data lakes are in the cloud, yet
While much of the focus for data lakes is on the cloud, among the technical user sessions at the Subsurface conference was one about an on-premises approach.
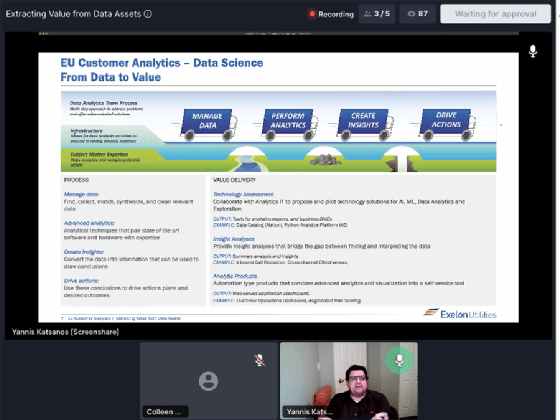
Yannis Katsanos, head of customer data science at Exelon Utilities, detailed in a session the on-premises data lake management and data analytics approach his organization takes.
Yannis Katsanos, head of customer data science at Exelon Utilities, explained how his organization gets value out of its massive data sets.
Exelon Utilities is one of the largest power generation conglomerates in the world, with 32,000 megawatts of total power-generating capacity. The company collects data from smart meters, as well as its power plants, to help inform business intelligence, planning and general operations. The utility draws on hundreds of different data sources for Exelon and its operations, Katsanos said.
"Every day I'm surprised to find out there is a new data source," he said.
To enable its data analytics system, Exelon has a data integration layer that involves ingesting all the data sources into an Oracle Big Data Appliance, using several technologies including Apache Kafka to stream the data. Exelon is also using Dremio's Data Lake Engine technology to enable structured queries on top of all the collected data.
While Dremio is often associated with cloud data lake deployments, Katsanos noted Dremio also has the flexibility to be installed on premises as well as in the cloud. Currently, Exelon is not using the cloud for its data analytics workloads, though, Katsanos noted, it's the direction for the future.
The evolution of data engineering to the data lake
The use of data lakes -- on premises and in the cloud -- to help make decisions is being driven by a number of economic and technical factors. In a keynote session, Tomasz Tunguz, managing director at Redpoint Ventures and a board member of Dremio, outlined the key trends that he sees driving the future of data engineering efforts.
Among them is a move to define data pipelines that enable organizations to move data in a managed way. Another key trend is the adoption of compute engines and standard document formats to enable users to query cloud data without having to move it to a specific data warehouse. There is also an expanding growing landscape of different data products aimed at helping users derive insight from data, he added.
"It's really early in this decade of data engineering; I feel as if we're six months into a 10-year-long movement," Tunguz said. "We need data engineers to weave together all of these different novel technologies into beautiful data tapestry."