Startup TileDB raises funds to advance universal data engine
A database technology project originally developed at MIT gets new funding that will help the startup database vendor grow and aim at a broader market.
Many databases rely on tables and columns to organize data, but that's not the approach used by TileDB and its open source database.
The vendor, based in Cambridge, Mass., takes an approach that uses a data array rather than a columnar format to organize data. An array enables the database to store different types of data items across multiple dimensions in a grid.
The TileDB technology also integrates what the company refers to as a "Universal Data Engine," a data management layer that separates access control and versioning, among other things, from storage. TileDB has a cloud database-as-a-service offering in addition to the core open source project.
The original technology behind TileDB was developed at MIT and then spun out as a standalone company in 2017. On July 14, TileDB made public its Series A round of funding, bringing in $15 million to help advance the vendor's technology and expand to more industries.
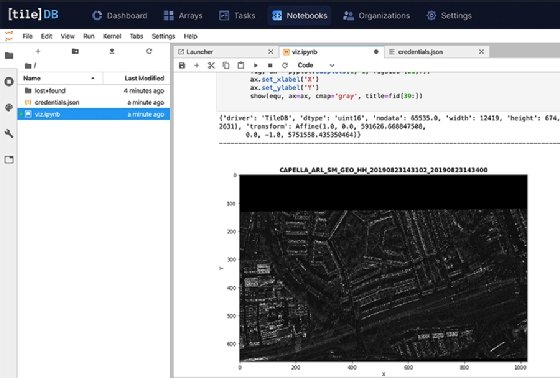
One of the initial use cases for TileDB has been in the geospatial sector, in which Capella Space is a user. Capella Space, based in San Francisco, provides high resolution space-based images of Earth to its own customer base and uses TileDB as an integrated part of its technology stack.
The TileDB database uses arrays to enable users to story different types of data, including geospatial images.
Scott Soenen, vice president of product engineering at Capella Space, said a key goal for his company is to help data scientists to be able to immediately dive into their analysis work, without having to worry about a lot of data reformatting and preprocessing.
TileDB allows us to make our data available to these users as directly accessible, analysis-ready, dense time series arrays with very fast access, rather than legacy geospatial data files.
"TileDB allows us to make our data available to these users as directly accessible, analysis-ready, dense time series arrays with very fast access, rather than legacy geospatial data files," Soenen said. "Having our data available in a high-performance, easy-to-use data science environment creates a fast lane for our users to extract valuable information from Capella data about the changing planet."
TileDB and the Universal Data Engine
Stavros Papadopoulos, CEO and original creator of TileDB, said the foundational idea behind his database was to create an optimized storage layer. The multi-dimensional data array model that TileDB uses does encompass tables, but it also does more, providing the ability to store any type of data, including images and video, he said.
He also noted that the computation layer of TileDB is pluggable, meaning it can work with different types of query languages and technology including SQL, as well as with linear algebra computation in Python.
"Why we chose arrays is because it is the best foundation for creating the universal data engine; that is our ambition," Papadopoulos said.
TileDB taking aim at more applications
To date, Papadopoulos noted that TileDB has been useful for the geospatial sector as well as genomics, but he is now gearing up to take on more markets, thanks in part to the new funding. Initially TileDB targeted just geospatial imaging and genomics because as a small startup, the company possessed limited resources and had to choose markets where it could make an immediate impact.
Another key reason why the vendor wasn't previously going after the broader market was because until the TileDB 2.0 release on May 5, its platform was missing a key feature known as heterogeneous dimensions. That meant TileDB had difficultly handling tables of different data frames natively.
"Up until that point, we were still considered a scientific solution, so people were perceiving us only for genomics or geospatial because we were not handling tables," Papadopoulos said.
Looking to future releases of TileDB, Papadopoulos said that the vendor's plan is to enable more collaboration features as well as enhanced database schema capabilities.