Lessons learned from Credit Karma GraphQL architecture
Credit Karma's vice president of engineering explains why and how the personal finance service is using the GraphQL data query technology to support its growing business.
Credit Karma and similar companies have transformed the personal finance market during the past two decades. Credit Karma has undergone multiple transformations since launching in 2007, culminating in reports this week from The New York Times and The Wall Street Journal that it will be acquired by Intuit in a deal valued at $7 billion. Credit Karma did not immediately respond to a request for confirmation of the acquisition.
While multiple technologies have helped spur Credit Karma's growth, in recent years the company has increasingly embraced GraphQL architecture as a way to improve its services with faster response times for its 100 million members. According to the company, approximately 50% of Credit Karma's data traffic flows through GraphQL.
San Francisco-based Credit Karma has been using GraphQL in production since 2017 and has steadily improved its deployment in the years since, developing its own federated GraphQL system. One of the key architects of Credit Karma's GraphQL architecture is Nick Nance, vice president of engineering at Credit Karma, who joined the company in 2016.
"One of my initial roles as I started with Credit Karma was help with the re-platforming of our technology stack," Nance said. "At that time, Credit Karma was really starting to reach hyper growth, and to support that we were growing our engineering team quite rapidly and needed to set up an architecture that would help support scaling."
From monolith to microservices with GraphQL
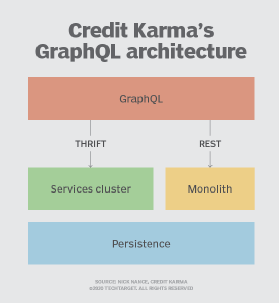
Nance said Credit Karma started out with a monolithic application stack and was looking to move to a microservices-based approach to help with scaling. As part of the move to microservices, Credit Karma engineers knew they needed to have an API gateway to help expose services but wanted to find an alternative approach -- which is how they found GraphQL.
We use GraphQL to expose services, but we also use it in a bit of a unique way in that we use it in what you can think of as a presentation layer.
Nick NanceVice president of engineering, Credit Karma
"We use GraphQL to expose services, but we also use it in a bit of a unique way in that we use it in what you can think of as a presentation layer," Nance said.
He added that Credit Karma doesn't directly expose a database. Instead, the GraphQL architecture is able to provide data to users in a structure that matches what the user will see on the device.
How Credit Karma's GraphQL infrastructure works
At the core of Credit Karma's GraphQL stack is a GraphQL server. When a request comes from the client application, such as a request to see a credit report, it first hits the GraphQL server. Nance said the GraphQL server in turn will connect to services that sit underneath it.
"Those services will then in turn access the database and provide the data back to the GraphQL server, that will then transform that data into the structure that the application needs to display to the user," he said.
Credit Karma purpose-built its own GraphQL server, though the company does make use of several open source efforts, including the Apollo GraphQL server project. Nance is a co-author of the project, which is part of a larger group of projects led by Apollo. Nance emphasized that he's a contributor to the Apollo GraphQL server project and is not using the commercially supported Apollo offerings at this time.
How Credit Karma has implemented GraphQL in its architecture as away to query data services.
"We do leverage open source projects but also have a lot of proprietary technology that is implemented into our GraphQL server, and that's all built in-house," he said.
GraphQL is sometimes deployed alongside graph databases, but that's not how Credit Karma's architecture is set up. Nance said Credit Karma is using standard relational databases like MySQL, and is not currently making use of graph database technologies.
Lessons learned from GraphQL architecture at scale
Though the experience of deploying GraphQL at scale at Credit Karma, there have been some key lessons learned. Nance said there are two key elements to GraphQL: the schema and queries. The schema defines what the graph looks and all the data available, while the queries are used to access that data.
"As you productize GraphQL, you need a way to maintain the schema and repository of all the queries that are used," he said. "So you need a mechanism to both maintain that library of queries and the schema and be able to iterate and evolve those two items independent of one another."
Another key lesson learned by the Credit Karma team has to do with scaling the GraphQL architecture, both in terms of size and sophistication. Nance said that as complexity and size of the graph grows, it can be difficult to change and manage.
"So when you when you reach that point, you have to get into what's called now federated GraphQL, and that's where you basically have different versions or different instances of GraphQL services that ultimately support the entire graph itself," Nance said.
He added that one of the challenges of GraphQL is because it has a single schema, it almost creates an architectural pattern that makes it a monolith.
"So you have to be really explicit about how you break that thing into little segments, and separate that out to kind of decompose it into something that's smaller and more manageable," he said.