Apache Kafka version 2.4 improves streaming data performance
The latest release of the Apache Kafka open source event streaming platform adds improved replication and availability capabilities to help boost overall performance.
ApacheKafka version 2.4 became generally available this week, bringing with it a host of new features and improvements for the widely deployed open source distributed streaming data technology.
The popularity of Kafka has put it at the center of event processing infrastructure, which is used by organizations of all sizes to stream messages and data. Kafka is often used as a technology that brings data into a database or a data lake, where additional processing and analytics occur. Optimizing performance for globally distributed Kafka deployments has long been a challenge, but the new features in Apache Kafka 2.4 could also help to further its popularity, with improved performance and lower latency.
"Kafka has become the default for new messaging selection decisions," Gartner analyst Merv Adrian said. "Legacy message broker choices are in place in some shops, but even then, some people are switching. "
Apache Kafka version 2.4 improves replication features
Adrian added that, from his perspective, the improvements to the MirrorMakerfunctionality in Kafka 2.4 are valuable additions. MirrorMaker is used to replicate topics between clusters, a key component for both performance and scalability. It has been challenging to handle replication in multi-cluster enterprise environments, he said, and that's where the commercially useful growth for Kafka is likely to be.
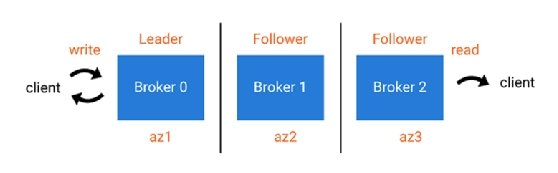
According to Tim Berglund, senior director of developer experience at Confluent, one of the key features in the Apache Kafka 2.4 release is the ability to allow consumers to fetch data from the closest replica. The feature is formally known as Kafka Improvement Proposal (KIP) 392.
With Apache Kafka 2.4's KIP-392, consumers can read from local brokers by supplying their own rack identifier when first talking to the leader.
"For the many organizations that are distributing application functionality across data centers, clouds and between regions and availability zones, the capability of closest-replica fetching makes Kafka better equipped to handle cloud-native deployments," Berglund said. Confluent is one of the leading commercial backers of Kafka and has its own enterprise platform that makes use of the open source project.
Another interesting feature in Apache Kafka version 2.4 is the ability to create an administrative API for replica reassignment. This feature makes APIs within Kafka more familiar, Berglund explained, and thus easier to use for the everyday developer. The feature replaces an existing Apache ZooKeeper-based API that had some limitations and complexity.
Kafka has become the default for new messaging selection decisions. Legacy message broker choices are in place in some shops, but even then, some people are switching.
Merv AdrianAnalyst, Gartner
"It consists of new methods added onto the AdminClient class, which is a popular API that's likely already in most complex applications," Berglund said. "The old way required interfacing with Zookeeper directly, which involved more moving parts, imposed burdens on unit and integration testing, and needed a separate, specialized API that solely existed to talk to ZooKeeper."
What's coming to Kafka in 2020
Application architectures and deployment modalities have changed significantly since Kafka's original release nearly a decade ago, according to Berglund. As such, he expects that Kafka will continue evolving to be more compatible with today's emerging trends in IoT, machine learning and hybrid cloud.
"In the near term, look out for more KIPs that tackle the substantial task of eliminating ZooKeeper and ones that make Kafka feel more at home in the cloud," Berglund said. "As the second-most active Apache Software Foundation project, we see it constantly improving, thanks to the passionate community of committers backing it."