Databricks contributes Delta Lake to the Linux Foundation
Databricks has found a new home at the Linux Foundation for its open source Delta Lake data lake project, in a bid to help grow a broader community and accelerate adoption.
The Databricks-led open source Delta Lake project is getting a new home and a new governance model at the Linux Foundation.
In April, the San Francisco-based data science and analytics vendor open sourced the Delta Lake project, in an attempt to create an open community around its data lake technology. After months of usage and feedback from a community of users, Databricks decided that a more open model for development, contribution and governance was needed and the Linux Foundation was the right place for that.
The move to the foundation, which is home to myriad open source collaborative projects including Linux, Kubernetes and GraphQL, was made public Oct. 16.
Among the many users of Delta Lake is Amsterdam-based Quby, which is in the business of designing energy management services and technology. Quby uses data and AI to tackle one of the world's toughest problems: saving energy. On a daily basis, Quby collects and processes terabytes of IoT data from more than 400,000 homes across Europe, according to Stephen Galsworthy, chief data officer at Quby.
"Delta Lake offers us the possibility to run both batch and streaming pipelines upon the same IoT data," Galsworthy said.
The Quby Waste Checker service gives personalized advice on inefficient appliances and behaviors in the home and is run as a batch process every day. In contrast, time-critical services, such as being alerted to problems with a heating system before the home gets uncomfortably cold, must run with minimal delay and need streaming technology. Delta Lake allows Quby to provide both types of services at the same time, Galsworthy said.
We are confident that this step will lead to wider adoption of this transformational technology so that others can use it to tackle some of the world's toughest problems.
Dr. Stephen GalsworthyChief data officer, Quby
"At Quby, we are strong believers in open source technology and thus are delighted to see that Delta Lake has moved to the Linux Foundation," Galsworthy said. "We are confident that this step will lead to wider adoption of this transformational technology so that others can use it to tackle some of the world's toughest problems."
Why Delta Lake was open sourced
Delta Lake first started as an internal project two years ago as a proprietary system and was developed with several large customers, explained Reynold Xin, co-founder and chief architect at Databricks.
"We realized that many of our customers are really struggling with getting data pipelines to work reliably, especially with cloud data links," Xin said.
After initially being open sourced in April and made available as a project on the GitHub source code repository, Xin said Databricks was surprised by the volume of adoption and the feedback. There were more than 30 external contributors, with some actually contributing major changes to the project.
Delta Lake data architecture
Smaller organizations that wanted to contribute were fine with Databricks running the project, Xin said. Even so, for some of the larger companies, there was a need for a more open governance model and transparency about how the project operates, which is why the project is now moving to the Linux Foundation. At the Linux Foundation the Delta Lake project will set up a multi-stakeholder governance model that enables more transparent collaboration and participation.
How Delta Lake works
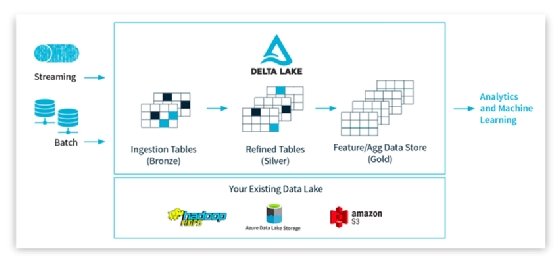
The Delta Lake architecture has a multi-tier process for refining data. A common pattern is for an organization to have an entire data engineering pipeline built with Apache Spark, with data going into Delta Lake, where it is incrementally refined.
At the first tier of the Delta Lake architecture is the bronze table where raw event data is stored, for example, an unparsed JSON string. At the silver level, the raw data is parsed and data can be extracted to derive more valuable information. Finally, at the gold level, data is further refined to the level of business metrics that an organization cares about.
Functionally, Delta Lake serves as an overlay on top of an existing data store, or data lake deployment.
"It doesn't replace your existing data lakes; it is just a layer on top," Xin said. "Its core is a protocol that describes metadata that is stored in an open format."
The protocol also enables a number of key features in Delta Lake, including the time travel feature, which provides a view into previous versions of data. If anything goes wrong with a data pipeline, time travel is a useful feature because it can help a user roll back to a known good state, Xin said.
Much of the focus in the coming months will be on how to enable the general ecosystem to better use the data in a Delta Lake. He noted that currently Delta Lake works well with Apache Spark, but as a Linux Foundation project, the overall goal is to become a broader standard for data lakes. As such, there is a need for Delta Lake to work well with other data pipeline tools and frameworks, beyond just Spark.
"The spirit behind Delta Lake is not just about storage, it's really about how to make data engineering and data science easier," Xin said.