Dremio Data Lake Engine 4.0 accelerates query performance
Dremio issues a new platform update, defining itself as data lake engine technology that looks to help users connect and query data faster in AWS and Azure.
Dremio is advancing its technology with a new release that supports AWS, Azure and hybrid cloud deployments, providing what the vendor refers to as a data lake engine.
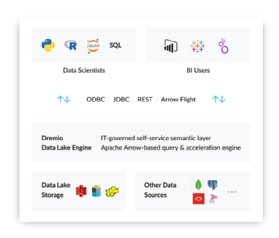
The Dremio Data Lake Engine 4.0 platform is rooted in multiple open source projects, including Apache Arrow, and offers the promise of accelerated query performance for data lake storage.
Dremio, which is based in Santa Clara, Calif., made the platform generally available on Sept. 17. The Dremio Data Lake Engine 4.0 update introduces a feature called column-aware predictive pipelining that helps predict access patterns, which makes queries faster. The new Columnar Cloud Cache (C3) feature in the software also boosts performance by caching data closer to where compute execution occurs.
For IDC analyst Stewart Bond, the big shift in the Dremio 4.0 update is how the vendor has defined its offering as an engine for data lakes focused on the AWS and Azure clouds.
In some ways, Dremio had previously struggled to define what its technology actually does, Bond said. In the past, Dremio had been considered a data preparation tool, a data virtualization tool and even a data integration tool, he said. It does all those things, but in ways, and with data, that differ markedly from traditional technologies in the data integration software market.
"Dremio offers a semantic layer, query and acceleration engine over top of object store data in AWS S3 or Azure, plus it can also integrate with more traditional relational database technologies," Bond said. "This negates the need to move data out of object stores and into a data warehouse to do analytics and reporting."
For data in a data lake to be valuable, it typically needs to be extracted, refined and delivered to data warehouses, analytics, machine learning, or operational applications where it can also be transformed into something different when blended with other data ingredients.
Stewart BondAnalyst, IDC
Simply having a data lake doesn't do much for an organization. A data lake is just data, and just as with natural lakes, water needs to be extracted, refined and delivered for consumption, Bond said.
"For data in a data lake to be valuable, it typically needs to be extracted, refined and delivered to data warehouses, analytics, machine learning or operational applications where it can also be transformed into something different when blended with other data ingredients," Bond said. "Dremio provides organizations with the opportunity to get value out of data in a data lake without having to move the data into another repository, and can offer the ability to blend it with data from other sources for new insights."
How Dremio Data Lake Engine 4.0 works
Organizations use technologies like extract, transform and load (ETL) tools, among other things, to move data from data lake storage into a data warehouse because they can't query the data fast enough where it is, said Tomer Shiran, co-founder and CTO of Dremio. That performance challenge is one of the drivers behind the C3 feature in Dremio 4.
"With C3 what we've developed is a patent pending real-time distributed cache that takes advantage of the NVMe devices that are on the instances that we're running on to automatically cache data from S3," Shiran explained. "So when the query engine is accessing a piece of data for the second time, it's at least 10 times faster than getting it directly from S3."
Dremio data lake architecture
The new column-aware predictive pipelining feature in Dremio Data Lake Engine 4.0 further accelerates query performance for the initial access. The features increases data read throughput to the maximum that is allowed on a given network, Shiran explained.
While Dremio is positioning its technology as a data lake engine that can be used to query data stored in a data lake, Shiran noted that the platform also has data virtualization capabilities. With data virtualization, pointers or links to sources of data enables creating a logical data layer.
Apache Arrow
One of the foundational technologies that enables the Dremio Data Lake Engine is the open source Apache Arrow project, which Shiran helped to create.
"We took the internal memory format of Dremio, and we open sourced that as Apache Arrow, with the idea that we wanted our memory format to be an industry standard," Shiran said.
Arrow has become increasingly popular over the past three years and is now used by many different tools, including Apache Spark.
With the growing use of Arrow, Dremio's goal is to make communications between its platform and other tools that use Arrow as fast as possible. Among the ways that Dremio is helping to make Arrow faster is with the Gandiva effort that is now built into Dremio 4, according to the vendor. Gandiva is an execution kernel that is based on the LLVM compiler, enabling real-time code compilation to accelerate queries.
Dremio will continue to work on improving performance, Shiran said.
"At the end of the day, customers want to see more and more performance, and more data sources," he said. "We're also making it more self-service for users, so for us we're always looking to reduce friction and the barriers."