operational intelligence (OI)

What is operational intelligence (OI)?
Operational intelligence (OI) is an approach to data analysis that enables decisions and actions in business operations to be based on real-time data as it's generated or collected by companies. Typically, the data analysis process is automated, and the resulting information is integrated into operational systems for immediate use by business managers and workers.
OI applications are primarily targeted at front-line workers who, hopefully, can make better-informed business decisions or take faster action on issues if they have access to timely business intelligence (BI) and analytics data. Examples include call-center agents, sales representatives, online marketing teams, logistics planners, manufacturing managers and medical professionals. In addition, operational intelligence can be used to automatically trigger responses to specified events or conditions.
What is now known as OI evolved from operational business intelligence, an initial step focused more on applying traditional BI querying and reporting. OI takes the concept to a higher analytics level, but operational BI is sometimes still used interchangeably with operational intelligence as a term.
How operational intelligence works
In most OI initiatives, data analysis is done in tandem with data processing or shortly thereafter, so workers can quickly identify and act on problems and opportunities in business operations. Deployments often include real-time business intelligence systems set up to analyze incoming data, plus real-time data integration tools to pull together different sets of relevant data for analysis.
Stream processing systems and big data platforms, such as Hadoop and Spark, can also be part of the OI picture, particularly in applications that involve large amounts of data and require advanced analytics capabilities. In addition, various IT vendors have combined data streaming, real-time monitoring and data analytics tools to create specialized operational intelligence platforms.
As data is analyzed, organizations often present operational metrics, key performance indicators (KPIs) and business insights to managers and other workers in interactive dashboards that are embedded in the systems they use as part of their jobs; data visualizations are usually included to help make the information easy to understand. Alerts can also be sent to notify users of developments and data points that require their attention, and automated processes can be kicked off if predefined thresholds or other metrics are exceeded, such as stock trades being spurred by prices hitting particular levels.
Operational intelligence uses and examples
Stock trading and other types of investment management are prime candidates for operational intelligence initiatives because of the need to monitor huge volumes of data in real time and respond rapidly to events and market trends. Customer analytics is another area that's ripe for OI. For example, online marketers use real-time tools to analyze internet clickstream data, so they can better target marketing campaigns to consumers. Cable TV companies track data from set-top boxes in real time to analyze the viewing activities of customers and how the boxes are functioning.
The growth of the internet of things has sparked operational intelligence applications for analyzing sensor data being captured from manufacturing machines, pipelines, elevators and other equipment; that enables predictive maintenance efforts designed to detect potential equipment failures before they occur. Other types of machine data also fuel OI applications, including server, network and website logs that are analyzed in real time to look for security threats and IT operations issues.
There are less grandiose operational intelligence use cases, as well. That includes the likes of call-center applications that provide operators with up-to-date customer records and recommend promotional offers while they're on the phone with customers, as well as logistics ones that help calculate the most efficient driving routes for fleets of delivery vehicles.
OI benefits and challenges
The primary benefit of OI implementations is the ability to address operational issues and opportunities as they arise -- or even before they do, as in the case of predictive maintenance. Operational intelligence also empowers business managers and workers to make more informed -- and hopefully better -- decisions on a day-by-day basis. Ultimately, if managed successfully, the increased visibility and insight into business operations can lead to higher revenue and competitive advantages over rivals.
But there are challenges. Building operational intelligence architecture typically involves piecing together different technologies, and there are numerous data processing platforms and analytics tools to choose between, some of which may require new skills in organizations. High performance and sufficient scalability are also needed to handle the real-time workloads and large volumes of data common in OI applications without choking the system.
Also, most business processes at a typical company don't require real-time data analysis. With that in mind, a key part of operational intelligence projects involves determining which end users need up-to-the-minute data and then training them to handle the information once it starts being delivered to them in that fashion.
Operational intelligence vs. business intelligence
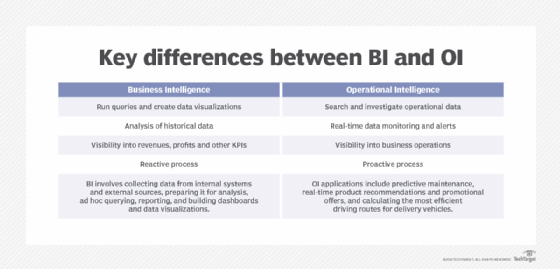
Conventional BI systems support the analysis of historical data that has been cleansed and consolidated in a data warehouse or data mart before being made available for business analytics uses. BI applications generally aim to tell corporate executives and business managers what happened in the past on revenues, profits and other KPIs to aid in budgeting and strategic planning.
Early on, BI data was primarily distributed to users in static operational reports. That's still the case in some organizations, although many have shifted to dashboards with the ability to drill down into data for further analysis. In addition, self-service BI tools let users run their own queries and create data visualizations on their own, but the focus is still mostly on analyzing data from the past.
Operational intelligence systems let business managers and front-line workers see what's currently happening in operational processes and then immediately act upon the findings, either on their own or through automated means. The purpose is not to facilitate planning, but to drive operational decisions and actions in the moment.






