How to build an all-purpose big data pipeline architecture
Like a superhighway system and its many on- and off-ramps, an enterprise's big data pipeline transports infinite amounts of collected data from its sources to its destinations.

The quickest and often most efficient way to move large volumes of anything from point A to point B is with some sort of pipeline. Whether associated with lanes on a superhighway or major arteries in the human body, pipelines can rapidly advance objects and enable them to easily diverge and perform tasks along the route. The same principle applies to a big data pipeline.
To put the term big data into context, when data and the frequency at which it's created are small, an email with an attached document will suffice for transferring it and a hard drive will suffice for storing it, said David Schaub, a big data engineer at Shell. When the data is small and the frequency is high, it makes sense to automate sending documents or storing them with a simple out-of-box tool. When it strains the limits of out-of-box tools for either transfer or storage, the data is considered "big."
"This necessitates a tool that takes more configuration than normal," Schaub explained. "A big data pipeline is tooling set up to control flow of such data, typically end to end, from point of generation to store."
What is a big data pipeline?
One of the more common reasons for moving data is that it's often generated or captured in a transactional database, which is not ideal for running analytics, said Vinay Narayana, head of big data engineering at Wayfair. To be most useful, this data often needs to be moved to a data warehouse, data lake or Hadoop file system (HDFS) -- or from one data store to another in batch or real time.
"The big data pipeline enables the handling of data flow from the source to the destinations, while calculations and transformations are done en route," noted Serge Vilvovsky, founder and CEO of cloud data lake security provider AltaStata and a member of the MIT Sloan cybersecurity consortium. "Using the pipelines, organizations can convert the data into competitive advantage for immediate or future decision-making."
Big data architecture and engineering can be complex. Therefore, software engineers with some experience in dealing with large amounts of data are generally involved in building a data pipeline. Some data, such as free text, may require data scientists.
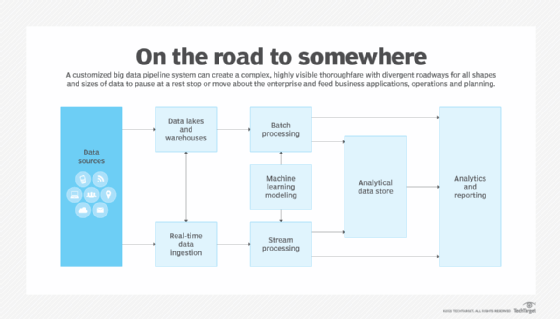
Why a big data pipeline architecture is important
A big data pipeline enables an organization to move and consolidate data from various sources to gain a unique perspective on what trends that data can reveal, said Eugene Bernstein, a big data developer at Granite Telecommunications.
Getting a big data pipeline architecture right is important, Schaub added, because data almost always needs some reconfiguration to become workable through other businesses processes, such as data science, basic analytics or baseline functionality of an application or program for which it was collected.
The process of moving data from one data store to another becomes harder when there are multiple data stores involved and they're spread across on-premises and public cloud data centers. This environment, Narayana said, is common these days as large enterprises continue migrating processes to the cloud.
Key stages and components in a data pipeline
The classic steps involved in a data pipeline are extract, transform and load (ETL). "After extracting the data," Vilvovsky detailed, "it must go through a cleanup process where only the necessary data fields are left and converted into formats suitable for computation. Multiple data sources may be joined by combining and aggregating procedures."
Data is first generated by a user or process and requires movement to some type of database. These steps are known as collection and ingestion. Raw data, Narayana explained, is initially collected and emitted to a global messaging system like Kafka from where it's distributed to various data stores via a stream processor such as Apache Flink, Storm and Spark.
At this stage, the data is considered partially cleansed. But it needs further processing before it can be productively used by other engineers, data scientists and analysts. Each of these groups may further process the data and store it in a data lake or warehouse, where it's ready to be used for recommendation, pricing and other models and for generating reports.
"Unstructured data such as free text can be converted into structured data, and interesting parts can be extracted from images and PDFs for future analysis," Schaub explained. "Sometimes, third-party data sources such as web search results can be used to enrich the data. The purpose of this process is to improve the usability of the data. Some confidential data may be deleted or hidden. In the final stage, the data should be ready to be loaded to the destination."
Different types of big data pipeline architectures
Organizations typically rely on three types of data pipeline transfers.
- Batch streaming refers to compiling chunks of data in temporary storage and sending it as a group on a schedule, Schaub said. This can be done when there are intermittent latency issues or when access to this data isn't urgent. "The batch approach," Vilvovsky added, "is based on periodically invoking the pipeline -- for example, once a day or week. The pipeline starts up, completes the chain of jobs and shuts down."
- Real-time streaming refers to data moving on to further storage and processing from the moment it's generated, such as a live data feed. "The streaming pipeline computes data from sensors and usually runs infinitely," Vilvovsky said. "From an implementation point of view, streaming data processing uses micro batches that execute within the short time windows."
- Lambda architecture attempts to combine batch and real-time streaming by having them sync to storing data in the same file by constantly appending to it. "This is very hard to do all in-house as the batch and real-time components are independently coded and must be in sync on the file writing," Schaub cautioned. "As such, this is most commonly done with a cloud service." Lambda architecture, Vilvovsky argued, "may or may not be applicable for batch and stream processing. AWS Lambda functions have some limitations. For example, Lambda timeout is 15 minutes, and the memory size limit is 10 GB. For short-term tasks that don't require a lot of memory per task, this is a very suitable approach. Lambda can scale to practically unlimited concurrency."
Examples of technologies for big data pipelines
Most organizations rely on products from multiple vendors to manage their data resources. Granite Telecommunications, Bernstein said, uses MapReduce, Hadoop, Sqoop, Hive and Impala for batch processing. Data comes from flat files or Oracle and SQL Server databases. For real-time processing, the company uses Kafka, PySpark, Hadoop, Hive and Impala.
A typical organization, Narayana said, has both batch and real-time data pipelines feeding a data warehouse, such as Snowflake, Redshift or BigQuery.
Both the batch and real-time data pipelines deliver partially cleansed data to a data warehouse. The data scientists and analysts typically run several transformations on top of this data before being used to feed the data back to their models or reports. Pipelines can also do ETL. Raw data is extracted from the source and quickly loaded into a data warehouse where the transformation occurs.
Best practices for building big data pipelines
In the process of scaling up a big data management system, many organizations end up with several data stores because of the flexibility they offer, Narayana said. These data stores include relational databases for transactional data, NoSQL databases for various types of data, Hadoop for batch processing, data warehouses for reporting, data lakes for advanced analytics and low-cost cloud object storage services, plus special-purpose technologies like Elasticsearch for logs and search and InfluxDB for time-series data.
"These are great choices for data stores," Narayana stressed, "but not so great for data processing by nonengineering groups such as data scientists and data analysts. Companies should provide seamless ways to build and operate data pipelines that are capable of moving data from one data store to the other at the lowest cost as it relates to the physical systems and operational overhead costs."
Big data pipelines, according to Schaub, should be the following:
- extensible to be able to incorporate as many other things as possible;
- scalable, so they can be sized up or down as demand on the system warrants. Sizing down is often forgotten but important for managing cloud costs; and
- idempotent, so they're able to produce the same result no matter how many times the same initial data is used. Logging should occur at the onset and completion of each step.
"Understand requirements to your functional, data size, memory, performance and cost constraints," Vilvovsky advised. "Choose the right architecture and frameworks. Make a prototype for one or two use cases and make sure it works. Use appropriate storage and security methods for your data type. Check out the new cloud services that are constantly emerging in the world. The architecture you want to create may already exist as a service."







