Hadoop Distributed File System (HDFS)
What is Hadoop Distributed File System (HDFS)?
The Hadoop Distributed File System (HDFS) is the primary data storage system Hadoop applications use. It's an open source distributed processing framework for handling data processing, managing pools of big data and storing and supporting related big data analytics applications.
HDFS employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters. It's designed to run on commodity hardware and is a key part of the many Hadoop ecosystem technologies.
How does HDFS work?
HDFS is built using the Java language and enables the rapid transfer of data between compute nodes. At its outset, it was closely coupled with MapReduce, a framework for data processing that filters and divides up work among the nodes in a cluster and organizes and condenses the results into a cohesive answer to a query. Similarly, when HDFS takes in data, it breaks the information down into separate blocks and distributes them to different nodes in a cluster.
The following describes how HDFS works:
- With HDFS, data is written on the server once and read and reused numerous times.
- HDFS has a primary NameNode, which keeps track of where file data is kept in the cluster.
- HDFS has multiple DataNodes on a commodity hardware cluster -- typically one per node in a cluster. The DataNodes are generally organized within the same rack in the data center. Data is broken down into separate blocks and distributed among the various DataNodes for storage. Blocks are also replicated across nodes, enabling highly efficient parallel processing.
- The NameNode knows which DataNode contains which blocks and where the DataNodes reside within the machine cluster. The NameNode also manages access to the files, including reads, writes, creates, deletes and the data block replication across the DataNodes.
- The NameNode operates together with the DataNodes. As a result, the cluster can dynamically adapt to server capacity demands in real time by adding or subtracting nodes as necessary.
- The DataNodes are in constant communication with the NameNode to determine if the DataNodes need to complete specific tasks. Consequently, the NameNode is always aware of the status of each DataNode. If the NameNode realizes that one DataNode isn't working properly, it can immediately reassign that DataNode's task to a different node containing the same data block. DataNodes also communicate with each other, which enables them to cooperate during normal file operations.
- The HDFS is designed to be highly fault tolerant. The file system replicates -- or copies -- each piece of data multiple times and distributes the copies to individual nodes, placing at least one copy on a different server rack than the other copies.
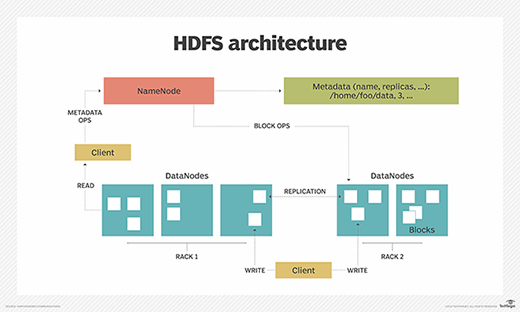
HDFS architecture, NameNode and DataNodes
HDFS uses a primary/secondary architecture where each HDFS cluster is comprised of many worker nodes and one primary node or the NameNode. The NameNode is the controller node, as it knows the metadata and status of all files including file permissions, names and location of each block. An application or user can create directories and then store files inside these directories. The file system namespace hierarchy is like most other file systems, as a user can create, remove, rename or move files from one directory to another.
The HDFS cluster's NameNode is the primary server that manages the file system namespace and controls client access to files. As the central component of the Hadoop Distributed File System, the NameNode maintains and manages the file system namespace and provides clients with the right access permissions. The system's DataNodes manage the storage that's attached to the nodes they run on.
NameNode
The NameNode performs the following key functions:
- The NameNode performs file system namespace operations, including opening, closing and renaming files and directories.
- The NameNode governs the mapping of blocks to the DataNodes.
- The NameNode records any changes to the file system namespace or its properties. An application can stipulate the number of replicas of a file that the HDFS should maintain.
- The NameNode stores the number of copies of a file, called the replication factor of that file.
- To ensure that the DataNodes are alive, the NameNode gets block reports and heartbeat data.
- In case of a DataNode failure, the NameNode selects new DataNodes for replica creation.
DataNodes
In HDFS, DataNodes function as worker nodes or Hadoop daemons and are typically made of low-cost off-the-shelf hardware. A file is split into one or more of the blocks that are stored in a set of DataNodes. Based on their replication factor, the files are internally partitioned into many blocks that are kept on separate DataNodes.
The DataNodes perform the following key functions:
- The DataNodes serve read and write requests from the clients of the file system.
- The DataNodes perform block creation, deletion and replication when the NameNode instructs them to do so.
- The DataNodes transfer periodic heartbeat signals to the NameNode to help keep HDFS health in check.
- The DataNodes provide block reports to NameNode to help keep track of the blocks included within the DataNodes. For redundancy and higher availability, each block is copied onto two extra DataNodes by default.
Features of HDFS
There are several features that make HDFS particularly useful, including the following:
- Data replication. Data replication ensures that the data is always available and prevents data loss. For example, when a node crashes or there's a hardware failure, replicated data can be pulled from elsewhere within a cluster, so processing continues while data is being recovered.
- Fault tolerance and reliability. HDFS' ability to replicate file blocks and store them across nodes in a large cluster ensures fault tolerance and reliability.
- High availability. Because of replication across nodes, data is available even if the NameNode or DataNode fails.
- Scalability. HDFS stores data on various nodes in the cluster, so as requirements increase, a cluster can scale to hundreds of nodes.
- High throughput. Because HDFS stores data in a distributed manner, the data can be processed in parallel on a cluster of nodes. This, plus data locality, cuts the processing time and enables high throughput.
- Data locality. With HDFS, computation happens on the DataNodes where the data resides, rather than having the data move to where the computational unit is. Minimizing the distance between the data and the computing process decreases network congestion and boosts a system's overall throughput.
- Snapshots. HDFS supports snapshots, which capture point-in-time copies of the file system and protect critical data from user or application errors.
What are the benefits of using HDFS?
There are seven main advantages to using HDFS, including the following:
- Cost effective. The DataNodes that store the data rely on inexpensive off-the-shelf hardware, which reduces storage costs. Also, because HDFS is open source, there's no licensing fee.
- Large data set storage. HDFS stores a variety of data of any size and large files -- from megabytes to petabytes -- in any format, including structured and unstructured data.
- Fast recovery from hardware failure. HDFS is designed to detect faults and automatically recover on its own.
- Portability. HDFS is portable across all hardware platforms and compatible with several operating systems, including Windows, Linux and macOS.
- Streaming data access. HDFS is built for high data throughput, which is best for access to streaming data.
- Speed. Because of its cluster architecture, HDFS is fast and can handle 2 GB of data per second.
- Diverse data formats. Hadoop data lakes support a wide range of data formats, including unstructured such as movies, semistructured such as XML files and structured data for Structured Query Language databases. Data retrieved via Hadoop is schema-free, so it can be parsed into any schema and can support diverse data analysis in various ways.
HDFS use cases and examples
HDFS can be used to manage pools of big data in several industries and scenarios, including the following:
- Electric companies. The power industry deploys phasor measurement units (PMUs) throughout their transmission networks to monitor the health of smart grids. These high-speed sensors measure current and voltage by amplitude and phase at selected transmission stations. These companies analyze PMU data to detect system faults in network segments and adjust the grid accordingly. For instance, they might switch to a backup power source or perform a load adjustment. PMU networks clock thousands of records per second, and consequently, power companies can benefit from inexpensive, highly available file systems, such as HDFS.
- Healthcare. HDFS is used in the healthcare industry to collect and analyze medical sensor data. For example, it makes it possible to collect and store volumes of data using sensors and equipment that are attached to patients. This data can be used for research, analysis and improved patient care.
- Marketing. Targeted marketing campaigns depend on marketers knowing a lot about their target audiences. Marketers can get this information from several sources, including customer relationship management systems, direct mail responses, point-of-sale systems and social media platforms. Because much of this data is unstructured, an HDFS cluster is the most cost-effective place to put data before analyzing it.
- Oil and gas providers. Oil and gas companies deal with a variety of data formats with very large data sets, including videos, 3D earth models and machine sensor data. An HDFS cluster can provide a suitable platform for the big data analytics that's needed.
- Scientific research. Analyzing data is a key part of scientific research, so HDFS clusters provide a cost-effective way to store, process and analyze large amounts of data generated from experiments, observations and simulations. It helps scientists evaluate large, intricate data sets, carry out computations using large sets of data and make new scientific discoveries.
- Telecommunications. Telecom businesses use HDFS to build effective network paths, suggest ideal places for network expansion, perform predictive maintenance on their infrastructure and study consumer behavior to guide the development of new service offerings. For example, telecommunication companies can carry out predictive maintenance on their infrastructure by using Hadoop powered analytics.
- Retail. Most retailers use Hadoop for understanding their customers better as it lets them view and analyze both structured and unstructured data.
- Machine learning and artificial intelligence. Applications involving AI and machine learning use HDFS as their data storage backbone. For instance, HDFS enables model training to be distributed and scaled up by effectively storing and retrieving the massive data sets needed to train machine learning models.
HDFS data replication
Data replication is an important part of the HDFS format as it ensures data remains available if there's a node or hardware failure. As previously mentioned, the data is divided into blocks and replicated across numerous nodes in the cluster and, except for the last block in a file, all block sizes are the same. Therefore, when one node goes down, the user can access the data that was on that node from other machines. HDFS maintains the replication process at regular intervals.
The following are some key functions and benefits HDFS data replication provides:
- Replication factor. The replication factor determines the number of copies that are made of each data block. Since the replication factor in HDFS is set to 3 by default, each data block is replicated three times. This guarantees that, in the event of a node failure or data corruption, several copies of the data block will be available.
- Data availability. HDFS replication makes data more available by enabling the storage of several copies of a given data block on various nodes. This guarantees that data can be accessible from other nodes even in the event of a temporary node outage.
- Placement policy. HDFS replicates data blocks according to a placement policy. When the replication factor is 3, HDFS places one replica on the local machine if the writer is on a DataNode, one on a random DataNode in the same rack and one on a separate node in a different rack. This placement policy provides data localization which reduces network traffic.
- Rack awareness. As HDFS is designed with rack awareness, it considers the cluster's network structure. This helps minimize the effects of rack failures on data availability by ensuring that duplicates of data blocks are distributed across different racks.
Big data apps can use a wide range of tools. Discover the top open source technologies and get more details about NoSQL databases.







