Cloud buoys data microservices -- for on-premises systems, too
Data in a microservices architecture is percolating anew. This news analysis looks at IBM Cloud Private for Data and other means to harmonize data in public and private locations.
It shouldn't be too startling to learn that cloud architectures are coming to data centers. Even if they are stuck on an organization's premises, today's enterprise architects want to get in on the action as data microservices evolve.
The cloud architectures they are bringing down to earth come largely via containers that are based on a microservices approach akin to old-time SOA -- which stands for service-oriented architecture, not Sons of Anarchy, the outlaw biker club from the TV show of the same name. Data microservices are like SOA, only more micro.
Improving big data support for containers was one of the engineering to-do list items cited by Hadoop vendors Cloudera and Hortonworks when they announced plans to merge this month. That and a move to wider use of cloud object storage represent a big shift coming to big data.
Kubernetes orchestration
While containers were born as stateless vessels, work is underway to make them more stateful, with support for persistence of data in applications. If successful, this could simplify the use of multiple for-purpose analytics engines and frameworks -- think Hive, Presto, Druid, TensorFlow and so on.
Used together with the increasingly popular Kubernetes container orchestration technology, data microservices will soon emerge as an alternative style of data processing, whether on the cloud or off.
It's early, and there is a lot of learning to do, as evidenced by Kubernetes sessions that were often full at last month's Strata Data Conference in New York. After learning comes building, much of which is necessary before the new architecture can take root.
Enter Cloud Private for Data
For IBM and its customers, finding a balance between on-premises and cloud data architectures is an ongoing quest. The company's vigorous embrace of both Hadoop and Spark has been noted before, but IBM is still working to neatly package those and other big data mainstays for cloud and on-premises deployments.
Near the end of the Strata conference, we spoke with Rob Thomas, general manager of IBM Analytics, as he prepared for a panel discussion on the company's IBM Cloud Private for Data platform and the role it can play in bringing AI to fruition. The Cloud Private for Data package includes Db2, Db2 Warehouse and Db2 Event Store, and it supports various interfaces for data scientists and other predictive analytics users, both on and off the cloud.
"If you built a model on private cloud, you can deploy it on public cloud. Or, if you built it on public cloud, you can deploy it on private cloud," Thomas said. The data preparation and governance tools are the same whether the deployment is public or private, he added.
Thomas said the company recently followed through on plans to add support for MongoDB, EnterpriseDB's EDB Postgres and IBM Data Risk Manager to IBM Cloud Private for Data, and it is working to certify the platform to work with Red Hat's OpenShift container application technology.
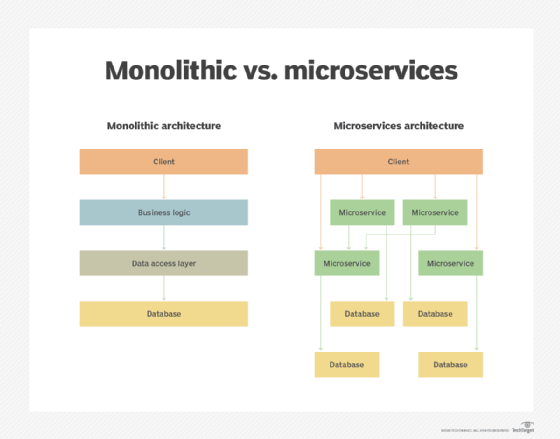
Monolithic vs. microservices
IBM's traditional data-side competitors are also looking to connect data analytics on premises with data analytics in the cloud. Oracle's efforts center on its Oracle Cloud at Customer undertaking. And Microsoft recently previewed a version of SQL Server 2019 that can bring the Azure versions of Spark and Hadoop down into the data center.
IBM has significant cloud development and data alliances with Red Hat and Hortonworks, both of which touch on data microservices. Both companies combined with IBM just before Strata to launch an Open Hybrid Architecture Initiative. The project's purpose is to meld Kubernetes, containers and Hadoop workloads, and there is much work to be done in that regard, Thomas said.
Remaking the monolithic
After Strata, we checked in with Tom Phelan, co-founder and chief architect at BlueData Software, maker of the software platform BlueData EPIC (Elastic Private Instant Clusters). He said he liked the goals of the Open Hybrid Architecture Initiative, but added that there must be more work before it can move forward.
"A big issue is that, when Hadoop was written, it was written as a monolithic architecture," Phelan said.
That is the case even though Hadoop can be broken down into services such as the name node, the YARN resource manager, Hive, Hadoop Distributed File System services and so on.
When Hadoop was written, it was written as a monolithic architecture.
Tom Phelanchief architect, BlueData
"None of those are microservice-architected," Phelan said. "Those services have to be started in a certain order. They have to interact with each other service in a very particular way. There is, for example, no way to restart one of those services and not have it impact other services that are running."
For its part, BlueData this month released KubeDirector, an open source project for developing stateful application clusters on Kubernetes.
New scheme coming?
Whether data moves to the cloud or not, the influence of cloud architecture looms as substantial.
"Companies obviously have a lot of on-premises data going into the cloud, but not all the data is going to the cloud," said Forrester analyst Noel Yuhanna. "Sometimes, when the cloud bill comes in, it may be huge -- maybe more than on premises."
Moves such as the Open Hybrid Architecture Initiative address the need to harmonize views in the two domains, according to Yuhanna, and set the stage for common management policies for both.
"You want an architecture that can manage both cloud and on-premises data with common policies," he added.
Back when SOA walked the earth, it brought about a reworking -- or rewrapping -- of legacy systems. New data microservices could make existing big data systems akin to legacy systems. That would be nothing more than progress.
It's a good bet that, as hybrid data processing becomes more real, data will be shuttling from here to there and back. And, of course, YANA -- Yet Another New Architecture -- will be waiting in the wings.