Data lake vs. data warehouse: Key differences explained
Data lakes and data warehouses are both commonly used in enterprises. Here are the main differences between them to help you decide which is best for your data needs.

The vast amount of data organizations collect from various sources goes beyond what regular relational databases can handle for BI, analytics and data science applications, creating the need for additional systems to manage the data. This leads to the question of a data lake vs. data warehouse -- when to use which one and how they compare to each other.
Both of these data repositories have a similar core function: housing business data for analysis and reporting. But they differ in their purpose and structure and in the types of data they store, where the data comes from and who typically accesses and uses it.
In general, the two repositories are fed by systems that generate data -- CRM, ERP, HR and financial applications, as well as mobile apps, real-time data streams, network and website logs, sensors and other sources. Data records from those sources are processed according to business rules and then sent to one of the repositories for ongoing storage and management.
Once the data from disparate business applications, IoT devices and external feeds is loaded onto a data lake or data warehouse platform, it can be used in data analytics tools to identify trends and deliver insights that help organizations make better-informed business decisions. At a high level, a data lake commonly holds varied sets of big data for advanced analytics applications, while a data warehouse stores conventional transaction data for basic BI, analytics and reporting uses. But let's look more closely at the two data stores and the differences between them.
What is a data lake?
A data lake is usually a vast repository that stores raw data in its native format. One benefit to a data lake is that it can store data of varying structures, not just traditional structured data. Each stored data element is tagged with a unique identifier and metadata so it can be queried more easily when needed. But data lakes don't require a predefined schema when data is ingested. Instead, data scientists and other analysts can apply a schema to data sets and filter them for specific analytics needs after the ingestion process is complete.
When they first emerged, data lakes were most commonly associated with the Hadoop distributed processing framework, but architecture options have increased to include other big data platforms as the influx of data continues to grow in organizations. Many IT vendors also now support data lakes in the cloud, often combining the Spark processing engine and cloud object storage services.
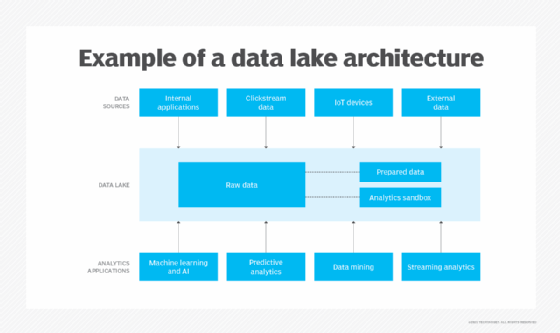
What is a data warehouse?
A data warehouse is a repository for data generated or collected by business applications and then stored for a predetermined analytics purpose. Most data warehouses are built on relational databases -- as a result, they do apply a predefined schema to data. In addition, the data typically must be cleansed, consolidated and organized for the intended uses before being loaded.
Because data in a data warehouse is already processed, it's relatively easy to do high-level analysis. Business managers and other workers who aren't skilled data or analytics professionals can use self-service BI tools to access and analyze the data on their own. An enterprise data warehouse provides a centralized data repository for an entire organization, while smaller data marts can be set up for individual departments. As with data lakes, cloud data warehouses increasingly are being deployed as an alternative to on-premises ones.
Data lake vs. data warehouse: 8 important differences
Organizations typically opt for a data warehouse over a data lake when they have a massive amount of data from operational systems that needs to be readily available for analysis to support day-to-day business processes. Data warehouses often serve as the single source of truth in an organization because they store historical business data that has been cleansed and categorized.
By comparison, a data lake often stores data from a wider variety of sources. A data lake platform is essentially a collection of various raw data assets that come from an organization's operational systems and other sources, often including both internal and external ones.
The following table details eight specific differences between data lakes and data warehouses:
| Data lake | Data warehouse | |
| Supported data types | Data lakes can handle a combination of structured, semistructured and unstructured data, which commonly is stored in its native format to make the full sets of raw data available for analysis. | Data warehouses typically store structured data from transaction processing systems and other business applications. In most cases, the data is cleansed and curated before going into a data warehouse. |
| Analytics uses | Data lakes are primarily used for data science applications that involve machine learning, predictive modeling and other advanced analytics techniques. Analytics goals aren't always predefined. | Data warehouses support less-complex BI, ad hoc analysis, reporting and data visualization applications, usually with a predefined purpose for analyzing business operations and tracking KPIs. |
| Users | Data scientists and lower-level data analysts are the primary users of data lakes. They're often supported by data engineers, who build data pipelines and help prepare data for analysis as needed. | Business analysts, executives and operational workers use data warehouses through self-service BI tools. Alternatively, BI analysts and developers run queries in data warehouses for business users. |
| Data processing methods | Data lakes support traditional extract, transform and load (ETL) processes, but they're more likely to use extract, load and transform, or ELT, in which data is loaded as is and transformed for specific uses. | ETL processes are common for data integration and preparation in data warehouses. The data structure is finalized before data sets are loaded to support the planned BI and analytics applications. |
| Schema approach | The schema for data sets can be defined after they're stored in a data lake, using a schema-on-read approach. | Schemas in data warehouses are defined before data sets are loaded, following schema-on-write practices. |
| Data storage | Data typically is stored in platforms other than relational databases, such as the Hadoop Distributed File System, cloud object storage services or NoSQL databases. | Most commonly, data is stored in relational databases using conventional disk storage. Data warehouses can also be built on columnar databases, similarly with disk storage. |
| Costs | Hardware costs can be less expensive because data lakes use lower-cost servers and storage. Data management might cost less, too. But the large size of some data lakes can erase the cost advantages. | In general, the large servers and disk storage systems required for data warehouses make them more expensive to deploy than data lakes. Managing a data warehouse can also be more costly. |
| Business benefits | Data lakes enable data science teams to analyze diverse sets of structured and unstructured data and create analytical models that provide insights for strategic planning and business decision-making. | Data warehouses provide a centralized repository of consolidated and curated data sets that can be easily accessed and used to analyze business performance and support operational decisions. |
To help remember the difference between a data lake and a data warehouse, picture actual warehouses and lakes: Warehouses store curated goods from specific sources, whereas a lake is fed by rivers, streams and other unfiltered sources of water. The same kind of distinction applies to their data counterparts, in a general sense.
Which platform is right for my organization?
Deciding on a data lake vs. a data warehouse depends mostly on how you plan to use your data.
Because data warehouses contain historical data that has already been processed and is ready to be used for analytics, it's well-suited for employees with less technical knowledge. Not only is it feasible for business analysts, executives and users to analyze data with self-service BI and analytics tools, the design of data warehouses often makes it easy for different teams and departments to access the data stored in them. This is why a well-built data warehouse architecture is key to breaking down data silos across enterprise systems.
A data lake approach is popular for organizations that ingest vast amounts of data in a constant stream from high-volume sources. Data ingestion is relatively uncomplicated because a data lake can store raw data. But such data is more difficult to navigate and work with than the processed data found in a data warehouse. As a result, data lakes are typically used by data scientists for advanced analytics applications. The flexibility they offer for building different analytical models from the same data sets also makes data lakes a popular choice for enterprises that have diverse analytics needs.
Ultimately, many organizations deploy both types of platforms to support different kinds of data analysis. There are also some cases where combining a data lake and a data warehouse in a unified environment could be the best option. For example, data from a data warehouse might be fed into a data lake for deeper analysis by data scientists. Going even further, new data lakehouse platforms have emerged that combine the flexible storage and scalability of a data lake with the data management and user-friendly querying capabilities of a data warehouse.







