An introduction to database transaction management
Find out the performance advantages of using one connection for multiple statements in this database tutorial. Get a definition of local vs. distributed transactions and learn how to manage database transactions.
 This chapter from The Data Access Handbook is designed to help you create a high-performing database. In this section you'll find out the advantages and disadvantages of using one connection for multiple statements. You'll also read definitions for local transactions vs. distributed transactions and learn how to manage transactions.
This chapter from The Data Access Handbook is designed to help you create a high-performing database. In this section you'll find out the advantages and disadvantages of using one connection for multiple statements. You'll also read definitions for local transactions vs. distributed transactions and learn how to manage transactions.
TABLE OF CONTENTS
- Designing for performance: Strategic database application deployments
- An introduction to database transaction management
- Executing SQL statements using prepared statements and statement pooling
- Database access security: network authentication or data encryption?
- Static SQL vs. dynamic SQL for database application performance
Advantages and Disadvantages
The advantage of using one connection for multiple statements is that it reduces the overhead of establishing multiple connections, while allowing multiple statements to access the database. The overhead is reduced on both the database server and client machines.
The disadvantage of using this method of connection management is that the application may have to wait to execute a statement until the single connection is available. We explained why in "How One Connection for Multiple Statements Works," page 17.
Guidelines for One Connection for Multiple Statements
Here are some guidelines for when to use one connection for multiple statements:
- Consider using this connection model when your database server has hardware constraints such as limited memory and one or more of the following conditions are true:
a. You are using a cursor-based protocol database.
b. The statements in your application return small result sets or no result sets.
c. Waiting for a connection is acceptable. The amount of time that is acceptable for the connection to be unavailable depends on the requirements of your application. For example, 5 seconds may be acceptable for an internal application that logs an employee's time but may not be acceptable for an online transaction processing (OLTP) application such as an ATM application. What is an acceptable response time for your application? - This connection model should not be used when your application uses transactions.
Case Study: Designing Connections
Let's look at one case study to help you understand how to design database connections. The environment details are as follows:
- The environment includes a middle tier that must support 20 to 100 concurrent database users, and performance is key. CPU and memory are plentiful on both the middle tier and database server.
- The database is Oracle, Microsoft SQL Server, Sybase, or DB2.
- The API that the application uses is ODBC, JDBC, or ADO.NET.
- There are 25 licenses for connections to the database server.
Here are some possible solutions:
- Solution 1: Use a connection pool with a maximum of 20 connections, each with a single statement.
- Solution 2: Use a connection pool with a maximum of 5 connections, each with 5 statements.
- Solution 3: Use a single connection with 5 to 25 statements.
The key information in this case study is the ample CPU and memory on both the middle tier and database server and the ample number of licenses to the database server. The other information is really irrelevant to the design of the database connections.
Solution 1 is the best solution because it performs better than the other two solutions. Why? Processing one statement per connection provides faster results for users because all the statements can access the database at the same time.
The architecture for Solutions 2 and 3 is one connection for multiple statements. In these solutions, the single connection can become a bottleneck, which means slower results for users. Therefore, these solutions do not meet the requirement of "performance is key."
Transaction Management
A transaction is one or more SQL statements that make up a unit of work performed against the database, and either all the statements in a transaction are committed as a unit or all the statements are rolled back as a unit. This unit of work typically satisfies a user request and ensures data integrity. For example, when you use a computer to transfer money from one bank account to another, the request involves a transaction: updating values stored in the database for both accounts. For a transaction to be completed and database changes to be made permanent, a transaction must be completed in its entirety.
What is the correct transaction commit mode to use in your application? What is the right transaction model for your database application: local or distributed? Use the guidelines in this section to help you manage transactions more efficiently.
You should also read the chapter for the standards-based API that you work with; these chapters provide specific examples for each API:
- For ODBC users, see Chapter 5.
- For JDBC users, see Chapter 6.
- For ADO.NET users, see Chapter 7.
Managing Commits in Transactions
Committing (and rolling back) transactions is slow because of the disk I/O and potentially the number of network round trips required. What does a commit actually involve? The database must write to disk every modification made by a transaction to the database. This is usually a sequential write to a journal file (or log); nevertheless, it involves expensive disk I/O.
In most standards-based APIs, the default transaction commit mode is autocommit. In auto-commit mode, a commit is performed for every SQL statement that requires a request to the database, such as Insert, Update, Delete, and Select statements. When auto-commit mode is used, the application does not control when database work is committed. In fact, commits commonly occur when there's actually no real work to commit.
Some database systems, such as DB2, do not support auto-commit mode. For these databases, the database driver, by default, sends a commit request to the database after every successful operation (SQL statement). This request equates to a network round trip between the driver and the database. The round trip to the database occurs even though the application did not request the commit and even if the operation made no changes to the database. For example, the driver makes a network round trip even when a Select statement is executed.
Because of the significant amount of disk I/O required to commit every operation on the database server and because of the extra network round trips that occur between the driver and the database, in most cases you will want to turn off auto-commit mode in your application. By doing this, your application can control when the database work is committed, which provides dramatically better performance.
Performance Tip
Although turning off auto-commit mode can help application performance, do not take this tip too far. Leaving transactions active can reduce throughput by holding locks on rows for longer than necessary, preventing other users from accessing the rows. Typically, committing transactions in intervals provides the best performance as well as acceptable concurrency
Consider the following real-world example. ASoft Corporation coded a standards-based database application and experienced poor performance in testing. Its performance analysis showed that the problem resided in the bulk five million Insert statements sent to the database. With auto-commit mode on, this meant an additional five million Commit statements were being issued across the network and that every inserted row was written to disk immediately following the execution of the Insert. When auto-commit mode was turned off in the application, the number of statements issued by the driver and executed on the database server was reduced from ten million (five million Inserts + five million Commits) to five million and one (five million Inserts + one Commit). As a consequence, application processing was reduced from eight hours to ten minutes. Why such a dramatic difference in time? There was significantly less disk I/O required by the database server, and there were 50% fewer network round trips.
If you have turned off auto-commit mode and are using manual commits, when does it make sense to commit work? It depends on the following factors:
- The type of transactions your application performs. For example, does your application perform transactions that modify or read data? If your application modifies data, does it update large amounts of data?
- How often your application performs transactions.
For most applications, it's best to commit a transaction after every logical unit of work. For example, consider a banking application that allows users to transfer money from one account to another. To protect the data integrity of that work, it makes sense to commit the transaction after both accounts are updated with the new amounts.
However, what if an application allows users to generate reports of account balances for each day over a period of months? The unit of work is a series of Select statements, one executed after the other to return a column of balances. In most cases, for every Select statement executed against the database, a lock is placed on rows to prevent another user from updating that data. By holding locks on rows for longer than necessary, active transactions can prevent other users from updating data, which ultimately can reduce throughput and cause concurrency issues. In this case, you may want to commit the Select statements in intervals (after every five Select statements, for example) so that locks are released in a timely manner.
In addition, be aware that leaving transactions active consumes database memory. Remember that the database must write every modification made by a transaction to a log that is stored in database memory. Committing a transaction flushes the contents of the log and releases database memory. If your application uses transactions that update large amounts of data (1,000 rows, for example) without committing modifications, the application can consume a substantial amount of database memory. In this case, you may want to commit after every statement that updates a large amount of data.
How often your application performs transactions also determines when you should commit them. For example, if your application performs only three transactions over the course of a day, commit after every transaction. In contrast, if your application constantly performs transactions that are composed of Select statements, you may want to commit after every five Select statements.
Isolation Levels
We will not go into the details of isolation levels in this book, but architects should know the default transaction isolation level of the database system they are using. A transaction isolation level represents a particular locking strategy used in the database system to improve data integrity.
Most database systems support several isolation levels, and the standards-based APIs provide ways for you to set isolation levels. However, if the database driver you are using does not support the isolation level you set in your application, the setting has no effect. Make sure you choose a driver that gives you the level of data integrity that you need.
Local Transactions Versus Distributed Transactions A local transaction is a transaction that accesses and updates data on only one database. Local transactions are significantly faster than distributed transactions because local transactions do not require communication between multiple databases, which means less logging and fewer network round trips are required to perform local transactions.
Use local transactions when your application does not have to access or update data on multiple networked databases.
A distributed transaction is a transaction that accesses and updates data on multiple networked databases or systems and must be coordinated among those databases or systems. These databases may be of several types located on a single server, such as Oracle, Microsoft SQL Server, and Sybase; or they may include several instances of a single type of database residing on numerous servers.
The main reason to use distributed transactions is when you need to make sure that databases stay consistent with one another. For example, suppose a catalog company has a central database that stores inventory for all its distribution centers. In addition, the company has a database for its east coast distribution center and one for the west coast. When a catalog order is placed, an application updates the central database and updates either the east or west coast database. The application performs both operations in one distributed transaction to ensure that the information in the central database remains consistent with the information in the appropriate distribution center's database. If the network connection fails before the application updates both databases, the entire transaction is rolled back; neither database is updated.
Distributed transactions are substantially slower than local transactions because of the logging and network round trips needed to communicate between all the components involved in the distributed transaction.
For example, Figure 2-6 shows what happens during a local transaction.
Figure 2-6 Local transaction
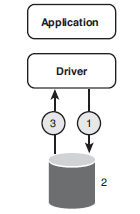
The following occurs when the application requests a transaction:
- The driver issues a commit request.
- If the database can commit the transaction, it does, and writes an entry to its log. If it cannot, it rolls back the transaction.
- The database replies with a status to the driver indicating if the commit succeeded or failed.
Figure 2-7 shows what happens during a distributed transaction, in which all databases involved in the transaction must either commit or roll back the transaction.
Figure 2-7 Distributed transaction
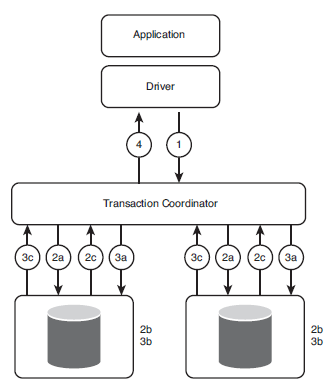
Note for Java users
The default transaction behavior of many Java application servers uses distributed transactions, so changing that default transaction behavior to local transactions, if distributed transactions are not required, can improve performance.
The following occurs when the application requests a transaction:
- The driver issues a commit request.
- The transaction coordinator sends a precommit request to all databases involved in the transaction.
- The transaction coordinator sends a commit request command to all databases.
a. Each database executes the transaction up to the point where the database is asked to commit, and each writes recovery information to its logs.
b. Each database replies with a status message to the transaction coordinator indicating whether the transaction up to this point succeeded or failed. - The transaction coordinator waits until it has received a status message from each database. If the transaction coordinator received a status message from all databases indicating success, the following occurs:
a. The transaction coordinator sends a commit message to all the databases.
b. Each database completes the commit operation and releases all the locks and resources held during the transaction.
c. Each database replies with a status to the transaction coordinator indicating whether the operation succeeded or failed. - The transaction coordinator completes the transaction when all acknowledgments have been received and replies with a status to the driver indicating if the commit succeeded or failed.
Copyright info
The Data Access Handbook by John Goodson and Robert A. Steward
ISBN 0137143931
First Printing March 2009
Prentice Hall Professional
More on accessing database:
- Read the next section — Executing SQL statements using prepared statements and statement pooling.
- Intrigued by this book excerpt? Download a free PDF of this chapter: Chapter 2 —Designing for Performance: What's Your Strategy?
- Read more excerpts and download more sample chapters from our Data Management bookshelf
- To purchase the book or similar titles, visit InformIT






