snowflaking (snowflake schema)

What is snowflaking (snowflake schema) in warehousing?
In data warehousing, snowflaking is a form of dimensional modeling in which dimensions are stored in multiple related dimension tables. A snowflake schema is a variation of the star schema that normalizes the dimension tables to increase data integrity, simplify data maintenance and reduce the amount of disk space. In certain situations, it can also improve query performance.
A star schema consists of a central fact table that references multiple dimension tables. Each dimension table is denormalized ("flattened") to avoid the query overhead that comes with a highly normalized schema, which can require a large number of joins to retrieve the necessary data.
Figure 1 shows a basic example of a star schema. It includes one fact table (green) and four dimension tables (blue). The fact table contains multiple foreign keys that reference the dimension tables. The data in each dimension table is denormalized, making queries fast and efficient.

Normalized dimension tables can contain a significant amount of redundant data. For instance, the dimTerritory table includes the TerritoryName, TerritoryCountry and TerritoryRegion columns. Together, these columns form the hierarchy TerritoryRegion > TerritoryCountry >TerritoryName. An example of this might be North America > Mexico > Baja California.
Columns such as TerritoryCountry and TerritoryName can have a low cardinality, which refers to the number of unique values relative to the number of rows. The more rows, the lower the cardinality and the more redundant data. Although data queries are generally faster in a star schema, the schema can also be more prone to data integrity issues and require more disk space than a more normalized structure.
In a snowflake schema, a fact is surrounded by its associated dimensions (as in a star schema), but those dimensions are further related to other dimensions, branching out into a snowflake pattern. Snowflaking normalizes the dimensions by moving attributes with low cardinality into separate dimension tables.
The fact table in a snowflake schema uses foreign keys to reference the core dimensions, which in turn use foreign keys to reference the dimensions at the next level. The illustration in Figure 2 shows a snowflake schema that was created from the star schema shown in Figure 1, with each of the original dimensions now normalized.
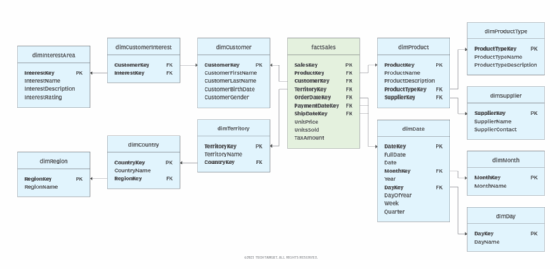
The fact table still links to the four core dimensions, but those dimensions have been normalized in the following ways:
- The dimCustomer dimension no longer includes the CustomerInterest1, CustomerInterest2 and CustomerInterest3 columns. Instead, a separate dimInterestArea table has been created, with a bridge (junction) table added between the dimInterestArea table and the dimCustomer table. The bridge table makes it possible to support a many-to-many relationship in which one customer can be associated with multiple interest areas and an interest area can be associated with multiple customers. It also enables customers to be associated with more than three interests.
- The ProductType and ProductSupplier columns in the dimProduct table have been replaced with key columns that reference the new dimProductType and dimSupplier tables, removing the redundant data from the dimProduct table.
- The hierarchical data in dimTerritory table is now fully normalized. The table contains a foreign key that references the dimCountry table and the dimCountry table contains a foreign key that references the dimRegion table. The data is now spread across the three dimension tables, eliminating the redundancy in the original dimTerritory table.
- The month and day data have been removed from the dimDate table and replaced with key columns that reference two new dimension tables, eliminating the many duplicated instances of the day and month names. The dimDate table can also be normalized in other ways, as warranted by the supported workloads and date range covered by the dimension.
Some sources consider a schema to be snowflaked if at least one of the dimensions is normalized, while other sources insist that all dimensions must be normalized. A schema that is only partially normalized is sometimes referred to as a starflake schema because it combines the characteristics of both the star and snowflake schemas.
What is the purpose of the snowflake schema?
The normalized dimensions in a snowflake schema reduce the amount of redundant data, making them less susceptible to data integrity issues than a star schema. Whenever multiple copies of the same data are stored in a database, as is the case with the star schema, there is a greater risk that extract, load and transform (ELT) operations will result in problems with the data.
With a snowflake schema, data maintenance is easier and less likely to cause data integrity issues. There is less redundant data, and that data is organized into separate tables, simplifying the processes of adding data and updating data. A snowflake schema also requires less disk space for data storage.
That said, a star schema is easier to set up than a snowflake schema. Developers can also build and update queries more easily, and those queries generally perform better because there are fewer joins. Many sources, including the Kimball Group, a data warehousing consultancy, generally recommend against the snowflake schema, although other sources, such as IBM, suggest that snowflaking is a viable alternative in some cases. However, snowflaking is rarely recommended simply to minimize disk space.
The snowflake schema might be used to support specific query needs, or it might be used when the data itself is not conducive to being easily denormalized. The decision to use a snowflake schema will often depend on the type of queries that will be supported and on the data being stored in the data warehouse. For instance, business intelligence (BI) applications that use a relational OLAP (ROLAP) architecture might perform better when the data warehouse schema is snowflaked.
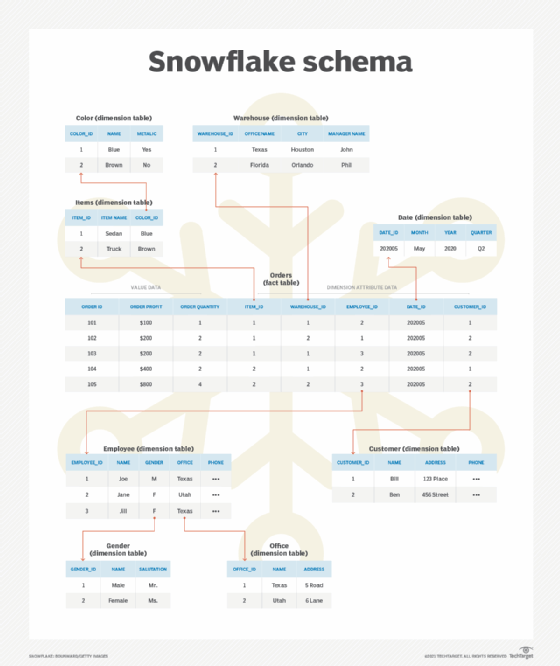
Snowflaking should also be considered when evaluating the dimensions themselves. For example, you should consider using it in the following circumstances:
- The dimension contains sparsely populated attributes whose values are mostly NULL.
- The dimension supports a many-to-many relationship but limits the number of potential instances. For example, a data warehouse for a streaming video service might have to limit the number of categories that can be associated with each video if the dimension is denormalized.
- The dimension is very large and full of redundant data in low cardinality attributes. For instance, a company's data warehouse might include a customer dimension that contains over a million rows of data, including a substantial amount of redundant geographical data.
- The dimension includes low cardinality attributes that are queried independently. For example, a product dimension might contain thousands of records, but only a handful of product types. Moving the product type attribute to its own dimension table can improve performance when the product types are queried independently.
- The dimension's attributes are part of a hierarchy and are queried independently, such as the year, quarter and month attributes of a date hierarchy or the country and state attributes of a geographic hierarchy.
Query performance will often drive the decision of whether to use a star schema or snowflake schema. However, data architects should still keep in mind other factors, such as data maintenance, data storage and the resources needed to develop and maintain the schema and queries.
Further explore the differences between star schema and snowflake schema and learn the differences between data lake vs. data warehouse.





