data profiling
What is data profiling?
Data profiling refers to the process of examining, analyzing, reviewing and summarizing data sets to gain insight into the quality of data. Data quality is a measure of the condition of data based on factors such as its accuracy, completeness, consistency, timeliness and accessibility.
Additionally, data profiling involves a review of source data to understand the data's structure, content and interrelationships.
This review process delivers two high-level values to the organization: It provides a high-level view of the quality of its data sets; and two, it helps the organization identify potential data projects.
Given those benefits, data profiling is an important component of data preparation programs. Its assistance helping organizations to identify quality data makes it an important precursor to data processing and data analytics activities.
Moreover, an organization can use data profiling and the insights it produces to continuously improve the quality of its data and measure the results of that effort.
This article is part of
What is data preparation? An in-depth guide to data prep
Data profiling may also be known as data archeology, data assessment, data discovery or data quality analysis.
Organizations use data profiling at the beginning of a project to determine if enough data has been gathered, if any data can be reused or if the project is worth pursuing. The process of data profiling itself can be based on specific business rules that will uncover how the data set aligns with business standards and goals.
Types of data profiling
There are three types of data profiling.
- Structure discovery. This focuses on the formatting of the data, making sure everything is uniform and consistent. It uses basic statistical analysis to return information about the validity of the data.
- Content discovery. This process assesses the quality of individual pieces of data. For example, ambiguous, incomplete and null values are identified.
- Relationship discovery. This detects connections, similarities, differences and associations among data sources.
What are the steps in the data profiling process?
Data profiling helps organizations identify and fix data quality problems before the data is analyzed, so data professionals aren't dealing with inconsistencies, null values or incoherent schema designs as they process data to make decisions.
Data profiling statistically examines and analyzes data at its source and when loaded. It also analyzes the metadata to check for accuracy and completeness.
It typically involves either writing queries or using data profiling tools.
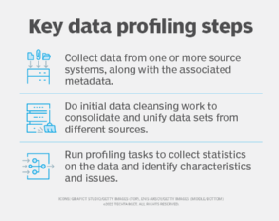
A high-level breakdown of the process is as follows:
- The first step of data profiling is gathering one or multiple data sources and the associated metadata for analysis.
- The data is then cleaned to unify structure, eliminate duplications, identify interrelationships and find anomalies.
- Once the data is cleaned, data profiling tools will return various statistics to describe the data set. This could include the mean, minimum/maximum value, frequency, recurring patterns, dependencies or data quality risks.
For example, by examining the frequency distribution of different values for each column in a table, a data analyst could gain insight into the type and use of each column. Cross-column analysis can be used to expose embedded value dependencies; inter-table analysis allows the analyst to discover overlapping value sets that represent foreign key relationships between entities.
Benefits of data profiling
Data profiling returns a high-level overview of data that can result in the following benefits:
- leads to higher-quality, more credible data;
- helps with more accurate predictive analytics and decision-making;
- makes better sense of the relationships between different data sets and sources;
- keeps company information centralized and organized;
- eliminates errors, such as missing values or outliers, that add costs to data-driven projects;
- highlights areas within a system that experience the most data quality issues, such as data corruption or user input errors; and
- produces insights surrounding risks, opportunities and trends.
Data profiling challenges
Although the objectives of data profiling are straightforward, the actual work involved is quite complex, with multiple tasks occurring from the ingestion of data through its warehousing.
That complexity is one of the challenges organizations encounter when trying to implement and run a successful data profiling program.
The sheer volume of data being collected by a typical organization is another challenge, as is the range of sources -- from cloud-based systems to endpoint devices deployed as part of an internet-of-things ecosystem -- that produce data.
The speed at which data enters an organization creates further challenges to having a successful data profiling program.
These data prep challenges are even more significant in organizations that have not adopted modern data profiling tools and still rely on manual processes for large parts of this work.
On a similar note, organizations that don't have adequate resources -- including trained data professionals, tools and the funding for them -- will have a harder time overcoming these challenges.
However, those same elements make data profiling more critical than ever to ensure that the organization has the quality data it needs to fuel intelligent systems, customer personalization, productivity-boosting automation projects and more.
Examples of data profiling
Data profiling can be implemented in a variety of use cases where data quality is important.
For example, projects that involve data warehousing or business intelligence may require gathering data from multiple disparate systems or databases for one report or analysis. Applying data profiling to these projects can help identify potential issues and corrections that need to be made in extract, transform and load (ETL) jobs and other data integration processes before moving forward.
Additionally, data profiling is crucial in data conversion or data migration initiatives that involve moving data from one system to another. Data profiling can help identify data quality issues that may get lost in translation or adaptions that must be made to the new system prior to migration.
The following four methods, or techniques, are used in data profiling:
- column profiling, which assesses tables and quantifies entries in each column;
- cross-column profiling, which features both key analysis and dependency analysis;
- cross-table profiling, which uses key analysis to identify stray data as well as semantic and syntactic discrepancies; and
- data rule validation, which assesses data sets against established rules and standards to validate that they're being followed.
Data profiling tools
Data profiling tools replace much, if not all, of the manual effort of this function by discovering and investigating issues that affect data quality, such as duplication, inaccuracies, inconsistencies and lack of completeness.
These technologies work by analyzing data sources and linking sources to their metadata to allow for further investigation into errors.
Furthermore, they offer data professionals quantitative information and statistics around data quality, typically in tabular and graph formats.
Data management applications, for example, can manage the profiling process through tools that eliminate errors and apply consistency to data extracted from multiple sources without the need for hand coding.
Such tools are essential for many, if not most, organizations today as the volume of data they use for their business activities significantly outpaces even a large team's ability to perform this function through mostly manual efforts.
Data profile tools also generally include data wrangling, data gap and metadata discovery capabilities as well as the ability to detect and merge duplicates, check for data similarities and customize data assessments.
Commercial vendors that provide data profiling capabilities include Datameer, Informatica, Oracle and SAS. Open source solutions include Aggregate Profiler, Apache Griffin, Quadient DataCleaner and Talend.






