
data lakehouse
What is a data lakehouse?
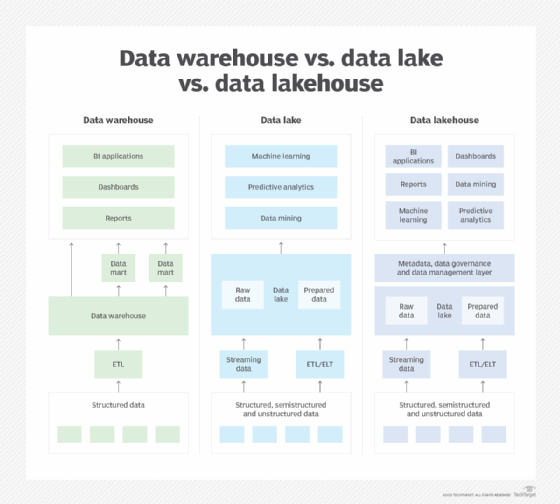
A data lakehouse is a data management architecture that combines the key features and the benefits of a data lake and a data warehouse. Data lakehouse platforms merge the rigorous data management functions, ease of access and data querying capabilities found in data warehouses with the data storage flexibility, scalability and relatively low cost of data lakes.
Like their two predecessors, data lakehouses support data analytics uses. But they're designed to handle both the business intelligence (BI) and reporting applications typically run against data warehouses and the more complex data science applications run against data lakes. In short, a data lakehouse makes that possible by adding data warehousing features on top of a data lake.
Data warehouses were first developed in the 1980s as a repository for structured data to support BI and basic analytics independent of the operational databases used for transaction processing. They also include features to enable high-performance SQL queries and ACID transactions, which apply the principles of atomicity, consistency, isolation and durability to ensure data integrity. But most data warehouses aren't suited to storing unstructured and semistructured data.
Data lakes originated with Hadoop clusters in the early 2000s and have since evolved to include other types of big data systems. They provide a lower-cost storage tier for a combination of structured, unstructured and semistructured data by using a file system or cloud object storage instead of the relational databases and disk storage common in data warehouses. While data lakes can store varied sets of big data, though, they often suffer issues with performance, data quality and inconsistencies due to the way the data in them is managed and modified for different analytics uses.
Data lakes and data warehouses require different processes for capturing and managing data from operational systems and other sources. To streamline things, organizations began developing a two-tier architecture in which data is first captured into a data lake. Some of the structured data is then converted into a SQL format and moved to a data warehouse, using extract, transform and load (ETL) processes or an alternative extract, load and transform (ELT) approach.
However, such architectures can lead to data processing delays, increased complexity and additional management overhead. Maintaining separate data platforms also results in significant capital expenditures and ongoing operational expenses. A data lakehouse, on the other hand, keeps all analytics data in a single platform that can be used more efficiently for BI, machine learning, predictive analytics, data mining and other applications.
What does a data lakehouse do?
The first documented use of the term data lakehouse was in 2017, but the lakehouse concept that has taken hold was initially outlined by data platform vendor Databricks in 2020 and then embraced by various other vendors. The goal is to eliminate the drawbacks of using data warehouses and data lakes: Data lakehouses are designed to provide broader analytics support than data warehouses do while avoiding the data management shortcomings that can limit the effectiveness of data lakes.
A data lakehouse can store a wide range of data from both internal and external sources and make it available to various end users, including the following:
- Data scientists.
- Data analysts.
- BI analysts and developers.
- Business analysts.
- Corporate and business executives.
- Marketing and sales teams.
- Manufacturing and supply chain managers.
- Operational workers.
Some or even all of the data is typically loaded and stored in a lakehouse in its original form. The raw data can be analyzed as is for certain applications, such as fraud or threat detection, and individual data sets are also cleansed, filtered and prepared as needed for other analytics uses.
How does a data lakehouse work?
In a data lakehouse environment, data from source systems is ingested into a data lake for storage, processing and analysis. That's done through different data integration methods, including batch ETL or ELT processes and real-time ones such as stream processing and change data capture. The data is then organized to support the traditional uses of both data lakes and data warehouses.
To enable those broad analytics applications, data lakehouses work in the following ways:
Data management. A data lakehouse combines support for easily ingesting raw data with strong data management features and the ability to process data for BI applications. Data lakes commonly use the Parquet or Optimized Row Columnar (ORC) file formats to organize data but offer limited capabilities for managing it. Data lakehouses include newer open source technologies, such as Delta Lake, Apache Hudi and Apache Iceberg, that support ACID transactions, indexing, data validation, version history, "time travel" to earlier versions of data, schema enforcement and other features on top of Parquet and ORC.
Multiple data layers. The data management capabilities enable a multilayered architecture with different levels of data processing and data cleansing. Sometimes referred to as a medallion architecture, such a setup typically includes a bronze layer with the raw data that's ingested into a data lakehouse; a silver layer with refined data that has been cleansed, conformed and validated; and a gold layer that contains curated, aggregated and enriched data.
Separation of storage and compute resources. Data storage and computing processes are decoupled and run on separate server clusters in data lakehouses. That means storage and compute capacity can be configured and scaled independently of each other for increased flexibility and more efficient resource utilization.
SQL performance tuning. In data warehouses, organizations are able to fine-tune data structures for the most common SQL queries. Data lakehouse users can similarly optimize the data layout for Parquet, ORC and other data lake file formats on the fly using SQL query engines to support data warehouse workloads.
Support for other programming languages. For advanced analytics applications, data lakehouses also provide the ability to use Python, Scala, Java and additional languages through application programming interfaces (APIs).
What are the features of a data lakehouse?
The key features of a data lakehouse include the following:
- Cloud object storage. A data lakehouse typically stores data in a low-cost and easily scalable cloud object storage service, such as Amazon Simple Storage Service, Microsoft's Azure Blob Storage and Google Cloud Storage.
- Transactional metadata layer. This sits on top of the underlying data lake and makes it possible to apply the data management and data governance features that are required for data warehouse operations and ACID transactions on the stored data.
- Data optimization capabilities. A data lakehouse also includes the ability to optimize data for faster analytics performance through measures such as clustering, caching and indexing.
- Open storage formats and APIs. Parquet, ORC and Apache Avro, another available data storage format, are open and standardized technologies. A data lakehouse also provides APIs for direct data access by analytics tools and SQL query engines.
- Various data types and workloads. Diverse sets of data can be stored in a data lakehouse and used in a variety of BI, analytics and data science applications, including both batch and streaming workloads.
What are the advantages and disadvantages of data lakehouses?
The main advantage of a data lakehouse is that it can simplify the overall analytics architecture by providing a single storage and processing tier for all data and all types of applications and use cases. This can streamline the data engineering process and make it easier to build data pipelines that deliver required data to end users for analysis.
Data lakehouses also address four problems with the two-tier architecture that spans separate data lake and data warehouse environments. That includes the following:
- Reliability issues. Data reliability can be improved by reducing brittle ETL data transfers among systems that often break due to data quality issues.
- Data staleness. This can be reduced because data often is available for all types of analytics in a few hours, compared to the multiple days it sometimes takes to cleanse and transform new data and transfer it into a data warehouse.
- Limits on advanced analytics. Advanced analytics applications that don't work well in traditional data warehouses can be executed more effectively on operational data in a lakehouse using data science tools such as TensorFlow, PyTorch, pandas and scikit-learn.
- High costs. Spending can decrease because data management teams only have to deploy and manage one data platform and a single-tier data lakehouse architecture requires less storage compared to two separate tiers.
The main disadvantage of the data lakehouse is that it's a relatively new kind of architecture. It's not yet entirely clear that organizations will see the gains promised by a unified platform that might be more difficult to upgrade and change down the road. Critics also claim that it can be hard to enforce data governance policies in a data lakehouse and that managing decoupled storage and compute resources can be complex. In addition, data engineers might need to master new skills related to using the metadata and data management layer to organize and optimize data for analytics applications.
What is the difference between a data lakehouse, data warehouse and data lake?
Data lakehouses differ from data warehouses and data lakes in that all data can be ingested and stored in one platform and fully managed there. Data sets in a data lakehouse can be processed and optimized for different kinds of queries and analytics uses. That can be done immediately after data is ingested for BI and analytics applications that end users run regularly or on the fly as needed to support new and special-purpose applications, especially data science, machine learning and big data analytics ones.
With data warehouses, all data must go through an ETL or ELT phase to be optimized for planned uses as it's being loaded or shortly after loading. This leads to fast performance on SQL analytics use cases, such as BI and reporting, but data warehouses traditionally have been limited to structured data and more basic types of analytics. However, some modern cloud data warehouse platforms can function in the same way as a data lakehouse, giving organizations a possible choice between the two technologies.
With a data lake, raw data from various internal and external sources can be ingested into a single object store and then organized and filtered for specific analytics uses. This enables organizations to capture different types of structured, semistructured and unstructured data for analysis. But the lack of data management and governance features supported in data warehouses -- and now data lakehouses -- can reduce the performance of analytics applications and lead to data quality issues.






