
data classification
What is data classification?
Data classification is the process of organizing data into categories that make it easy to retrieve, sort and store for future use. A well-planned data classification system makes essential data easy to find and retrieve. This can be of particular importance for risk management, legal discovery and regulatory compliance.
Written procedures and guidelines for data classification policies should define what categories and criteria the organization will use to classify data. They also specify the roles and responsibilities of employees within the organization regarding data stewardship.
Once a data classification scheme is created, security standards should be identified that specify appropriate data handling practices for each category. Storage standards that define the data's lifecycle requirements must be addressed as well.
What is the purpose of data classification?
Systematic classification of data helps organizations manipulate, track and analyze individual pieces of data. Data professionals often have a specific goal when categorizing data. The goal affects the approach they take and the classification levels and definitions they use.
This article is part of
What is data security? The ultimate guide
Some common business goals for data classification projects include the following:
- Confidentiality. A classification system can help safeguard highly sensitive data, such as customers' personally identifiable information (PII), including credit card numbers, Social Security numbers and other vulnerable data types. Establishing a classification system helps an organization focus on confidentiality and security policy requirements, such as user permissions and encryption.
- Data integrity. A system that focuses on data integrity requires more storage resources and more sophisticated user permissions and access control.
- Data availability. Addressing information security and integrity makes it easier to know what data can be shared with specific users.
Why data classification is important
Data classification is an important part of data lifecycle management that specifies which standard category or grouping a data object should be assigned to. Once sorted, data classification can help ensure an organization adheres to its data handling guidelines, and to local, state and federal compliance regulations, such as the Health Insurance Portability and Accountability Act, or HIPAA, and the Federal Information Processing Standard that the National Institute of Standards and Technology oversees. Companies in highly regulated industries often implement data classification processes or workflows to aid in compliance audit and data discovery processes.
Data classification is typically used to categorize structured data, but it is especially important when applied to unstructured data. Unstructured data lacks clear labels, so classification makes this data more usable and easier to search or query. Data categorization also helps identify duplicate copies of data. Eliminating redundant data contributes to efficient use of storage and maximizes data security measures.
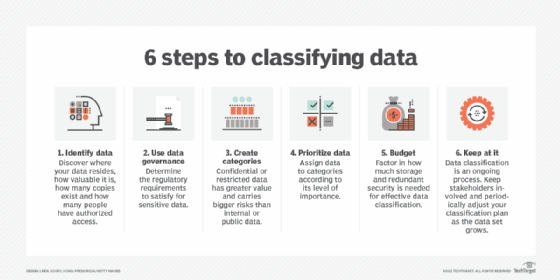
Common data classification steps
Not all data needs to be classified. In some cases, it isn't necessary to retain data, so destroying it is the prudent course of action. Understanding why data needs to be classified is an important part of the process.
Steps involved in developing a comprehensive set of policies to govern data include the following:
- Gather information. At the start of a data categorization project, organizations must identify and inspect the data that needs to be retained and classified or reclassified. It's important to know where it resides, how valuable it is, how many copies exist and who has access to it.
- Develop a framework. Data scientists and other stakeholders collaborate to develop a framework within which to organize the data, including assigning metadata or other tags to the information. This approach enables machines and software to instantly identify the groups and categories to which a data object belongs. Any information about the data, from file type to character units to size of data packets, can be used to sort and organize data into searchable, sortable categories.
- Apply standards. Companies must ensure their data classification strategy conforms to their internal data protection and handling practices, and reflects industry standards and customer expectations. Unauthorized disclosure of sensitive information, such as protected health information or biometric data, could be a breach of protocol and, in some countries, a crime. To enforce proper protocols and protect against data breaches, the data must be categorized and sorted according to its degree of data sensitivity.
- Process data. This step ensures that items in a database can be identified and sorted according to the established data classification framework.
Types of data classification
Standard data classification levels or categories include the following:
- Public information. Public data in this category is typically maintained by state institutions and subject to disclosure as related to certain laws. For example, aggregated information about a population or different agencies' activities and disclosures fall into this category.
- Confidential information. Confidential data might have legal restrictions in place regarding the way it's handled. There might be other consequences related to how confidential data is handled. Information documenting how a company's product is made or configured would be considered confidential information.
- Sensitive information. This data is any restricted data stored or handled by government or other institutions that have authorization or authentication requirements and other rules associated with its use. An organization's nonpublic financial information would fall within this category. All PII is considered sensitive information.
- Personal information. PII is protected by law and must be handled according to certain protocols. An example would be a person's Social Security number.
Examples of data classification
A number of different category lists can be applied to the information in a system. These lists of qualifications are also known as data classification schemes. For example, one way to classify data's level of sensitivity might include classes such as secret, confidential, business use only and public.
An organization might also use a system that classifies information based on the type of content in files, looking for certain common characteristics. For example, context-based classification examines applications, users, geographic location and creator info. User classification is based on what an end user chooses to create, edit and review.
Data classification and data parsing
In computer programming, file parsing is a method of splitting data packets into smaller subpackets that are easier to move, manipulate, categorize and sort. Different parsing styles determine how a system incorporates information. For instance, dates are split up by day, month or year, and words might be separated by spaces.
Some standard approaches to data classification using parsing include the following:
- Manual intervals. With manual intervals, a person reviews the entire data set and enters class breaks by observing where they make the most sense. This is a fine system for smaller data sets, but it can prove problematic for larger collections of information.
- Defined intervals. Defined intervals specify a number of characters to include in a packet. For example, information might be broken into smaller packets every three units.
- Equal intervals. Equal intervals divide a data set into a specified number of groups, distributing the amount of data evenly across the groups.
- Quantiles. Using quantiles involves setting a number of data values allowed per class type.
- Natural breaks. A program determines where changes in the data occur and uses those indicators as a way of determining where to break up the data.
- Geometric intervals. For geometric intervals, the same number of units is allowed per class category.
- Standard deviation intervals. The standard deviation of a data entry is determined by the degree to which its attributes differ from the norm. There are set number values to show each entry's deviations.
- Custom ranges. Users create and set custom ranges. They can change them at any point.
Tools used for data classification
Various tools are used in data classification, including databases, data management systems and business intelligence software. Some examples of BI software tools that help simplify data classification include Databox, Google Looker Studio and SAP Lumira.
Developers and data scientists use these tools to pull specific kinds of data to complete classification tasks faster. Other methods can be used to assist in applying data classification. For example, a regular expression is an equation used to quickly pull data that fits a certain category, making it easier to categorize all information that falls within those particular parameters.
Benefits of data classification
Data classification methods are useful to an organization for multiple reasons:
- Security and confidentiality. Using data classification helps organizations maintain the security, confidentiality and integrity of their data. Data that's labeled as more sensitive will have stronger security measures applied to it.
- Reducing costs. Classification also helps companies avoid paying increasing data storage costs. Storing data volumes that are excessive, unorganized and not likely to be accessed in their native states is expensive and can be a liability.
- Compliance. Various federal, state and local compliance standards can be met more easily when data is organized according to levels of sensitivity.
- Ease of access. Data that pertains to a specific scenario can be more easily found and queried with labels that reflect its content or metadata.
How does data classification help with compliance and security?
Data classification that's conducted with enough specificity ensures an organization pinpoints which data sets are public, confidential, sensitive and why. Classification lets an organization apply the proper security tools, such as encryption, access controls or data loss prevention, to ensure that restricted data isn't accessible to the wrong audiences and can't be tampered with. Additionally, classification ensures a trail documenting how data is used.
For unstructured data in particular, data classification makes it less vulnerable to breaches. For example, merchants and other businesses that accept credit cards are expected to comply with the data classification and other Payment Card Industry's Data Security Standards. PCI DSS is a set of 12 security requirements aimed at safeguarding customer financial information.
Data classification and the General Data Protection Regulation
The European Union (EU) adopted the General Data Protection Regulation (GDPR) in 2016. The GDPR is a set of international guidelines created to help ensure that companies and institutions handle confidential and sensitive data carefully and respectfully. The regulation went into effect in early 2018. It's made up of seven guiding principles: fairness, limited scope, minimized data, accuracy, storage limitations, rights and integrity. The GDPR prescribes stiff penalties for not complying with these standards.
Implementing methodical data classification is a necessity to comply with the many parts of GDPR. It requires organizations handling data on EU citizens to assign specific security control levels to it to prevent unauthorized access or disclosure. Classifying data helps data security teams identify data that requires anonymization or encryption.
Another aspect of GDPR that requires effective data classification is that it gives individuals the right to access, change and delete their personal data. Data classification makes it possible for companies to quickly retrieve such data and fulfill a person's specific request.
What is data reclassification?
To keep data classification systems as efficient as possible, it's important for an organization to continuously update the classification systems it uses. It might be necessary to reassign the values, ranges and outputs of these systems to more effectively meet the organization's evolving classification goals. There are a number of reasons why a business would need to engage in reclassification, including ensuring accuracy, mitigating risks, addressing security and cybersecurity concerns, and complying with local, state and federal regulations.
Implementing a policy to codify periodic reviews of data classification is a sound strategy to achieve this. Employees or managers delegated with data ownership can work with security and compliance officers to develop and enforce such a policy. It should address both internal changes and evolving compliance standards that would warrant data reclassification. It should also introduce new data categories as needed.
Data governance is important for organizations using data as part of their business. Find out more about data governance and how it lowers data risk, ensuring data is consistent, trustworthy and not misused.







