What is Extract, Load, Transform (ELT)?

Extract, Load, Transform (ELT) is a data integration process for transferring raw data from a source server to a data system (such as a data warehouse or data lake) on a target server and then preparing the information for downstream uses.
ELT is comprised of a data pipeline with three different operations being performed on data:
The first step is to Extract the data. Extracting data is the process of identifying and reading data from one or more source systems, which may be databases, files, archives, ERP, CRM or any other viable source of useful data.
The second step for ELT, is to Load the extract data. Loading is the process of adding the extracted data to the target database.
The third step is to Transform the data. Data transformation is the process of converting data from its source format to the format required for analysis. Transformation is typically based on rules that define how the data should be converted for usage and analysis in the target data store. Although transforming data can take many different forms, it frequently involves converting coded data into usable data using code and lookup tables.
Examples of transformations include:
- Replacing codes with values
- Aggregating numerical sums
- Applying mathematical functions
- Converting data types
- Modifying text strings
- Combining data from different tables and databases
How ELT works
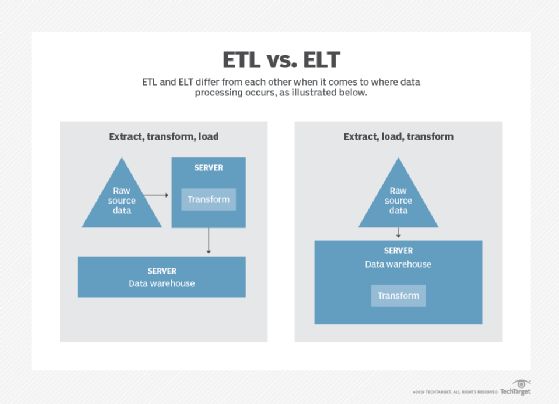
ELT is a variation of the Extract, Transform, Load (ETL), a data integration process in which transformation takes place on an intermediate server before it is loaded into the target. In contrast, ELT allows raw data to be loaded directly into the target and transformed there.
With an ELT approach, a data extraction tool is used to obtain data from a source or sources, and the extracted data is stored in a staging area or database. Any required business rules and data integrity checks can be run on the data in the staging area before it is loaded into the data warehouse. All data transformations occur in the data warehouse after the data is loaded.
ELT vs. ETL
The differences between ELT and a traditional ETL process are more significant than just switching the L and the T. The biggest determinant is how, when and where the data transformations are performed.
With ETL, the raw data is not available in the data warehouse because it is transformed before it is loaded. With ELT, the raw data is loaded into the data warehouse (or data lake) and transformations occur on the stored data.
Staging areas are used for both ELT and ETL, but with ETL the staging areas are built into the ETL tool being used. With ELT, the staging area is in a database used for the data warehouse.
ELT is most useful for processing the large data sets required for business intelligence (BI) and big data analytics. Nonrelational and unstructured data is more conducive for an ELT approach because the data is copied "as is" from the source. Applying analytics to unstructured data typically uses a "schema on read" approach as opposed to the traditional "schema on write" used by relational databases.
Loading data without first transforming it can be problematic if you are moving data from a nonrelational source to a relational target because the data will have to match a relational schema. This means it will be necessary to identify and massage data to support the data types available in the target database.
Data type conversion may need to be performed as part of the load process if the source and target data stores do not support all the same data types. Such problems can also occur when moving data from one relational database management system (DBMS) to another, such as say Oracle to Db2, because the data types supported differ from DBMS to DBMS.
ETL should be considered as a preferred approach over ELT when there is a need for extensive data cleansing before loading the data to the target system, when there are numerous complex computations required on numeric data and when all the source data comes from relational systems.
The following chart compares different facets of ETL or ELT:
|
|
ELT |
ETL |
| Order of Processes |
Extract |
Extract |
| Flexibility |
Because transformation is not dependent on extraction, ELT is more flexible than ETL for adding more extracted data in the future. |
More upfront planning should be conducted to ensure that all relevant data is being integrated. |
| Administration |
More administration may be required as multiple tools may need to be adopted. |
Typically, a single tool is used for all three stages perhaps simplifying administration effort. |
| Development Time |
With a more flexible approach, development time may expand depending upon requirements and approach. |
ETL requires upfront design planning, which can result in less overhead and development time because only relevant data is processed. |
| End Users |
Data scientists and advanced analysts |
Users reading reports and SQL coders |
| Complexity of Transformation |
Transformations are coded in by programmers (e.g., using Java) and must be maintained like any other program. |
Transformations are coded in the ETL tool by data integration professional experienced with the tool. |
| Hardware Requirements |
Typically, ELT tools do not require additional hardware, instead using existing compute power for transformations. |
It is common for ETL tools to require specific hardware with their own engines to perform transformations. |
| Skills |
ELT relies mostly on native DBMS functionality, so existing skills can be used in most cases. |
ETL requires additional training and skills to learn the tool set that drives the extraction, transformation and loading. |
| Maturity |
ELT is a relatively new practice, and as such there is less expertise and fewer best practices available. |
ETL is a mature practice that has existed since the 1990s. There are many skilled technicians, best practices exist, and there are many useful ETL tools on the market. |
| Data Stores |
Mostly Hadoop, perhaps NoSQL database. Rarely relational database. |
Almost exclusively relational database. |
| Use Cases |
Best for unstructured data and nonrelational data. Ideal for data lakes. Can work for homogeneous relational data, too. Well-suited for very large amounts of data. |
Best for relational and structured data. Better for small to medium amounts of data. |
Benefits of ELT
One of the main attractions of ELT is the reduction in load times relative to the ETL model. Taking advantage of the processing capability built into a data warehousing infrastructure reduces the time that data spends in transit and is usually more cost-effective. ELT can be more efficient by utilizing the computer power of modern data storage systems.
When you use ELT, you move the entire data set as it exists in the source systems to the target. This means that you have the raw data at your disposal in the data warehouse, in contrast to the ETL approach where the raw data is transformed before it is loaded to the data warehouse. This flexibility can improve data analysis, enabling more analytics to be performed directly within the data warehouse without having to reach out to the source systems for the untransformed data.
Using the ELT can make sense when adopting a big data initiative for analytics. Big data often relies on a large amount of data, as well as wide variety of data that is more suitable for ELT.
Uses of ELT
ELT is often used in the following cases:
- when the data is structured, but the source and target database are the same type (i.e., Oracle source and target);
- when the data is unstructured and massive, such as processing and correlating data from log files and sensors'
- when the data is relatively simple, but there are large amounts of it;
- when there is a plan to use machine learning tools to process the data instead of traditional SQL queries; and
- schema on read.
ELT tools and software
Although ELT can be performed using separate tools for extracting, loading and transforming the data, tools exist that integrate all ELT processes. When seeking an ELT tool, users should look for the ability to read data from multiple sources, specifically the sources that their organization uses and intends to use. Most tools support a wide variety of source and target data stores and database systems.
Users can look for tools that can perform both ETL and ELT, as it's likely to have the need for both data integration techniques.
Although there are many ELT/ETL tool providers, a few of the market leaders include:
- IBM
- Informatica
- Microsoft
- Oracle
- SAS
- Talend
- Teradata
A data store can be useful for managing a target data mart, data warehouse and/or data lake. For an ELT approach, NoSQL database management systems and Hadoop are viable candidates, as are purpose-built data warehouse appliances. In some cases, a traditional relational DBMS may be appropriate.







