Apache Hadoop YARN
Apache Hadoop YARN is the resource management and job scheduling technology in the open source Hadoop distributed processing framework. One of Apache Hadoop's core components, YARN is responsible for allocating system resources to the various applications running in a Hadoop cluster and scheduling tasks to be executed on different cluster nodes.
YARN stands for Yet Another Resource Negotiator, but it's commonly referred to by the acronym alone; the full name was self-deprecating humor on the part of its developers. The technology became an Apache Hadoop subproject within the Apache Software Foundation (ASF) in 2012 and was one of the key features added in Hadoop 2.0, which was released for testing that year and became generally available in October 2013.
The addition of YARN significantly expanded Hadoop's potential uses. The original incarnation of Hadoop closely paired the Hadoop Distributed File System (HDFS) with the batch-oriented MapReduce programming framework and processing engine, which also functioned as the big data platform's resource manager and job scheduler. As a result, Hadoop 1.0 systems could only run MapReduce applications -- a limitation that Hadoop YARN eliminated.
Before getting its official name, YARN was informally called MapReduce 2 or NextGen MapReduce. But it introduced a new approach that decoupled cluster resource management and scheduling from MapReduce's data processing component, enabling Hadoop to support varied types of processing and a broader array of applications. For example, Hadoop clusters can now run interactive querying, streaming data and real-time analytics applications on Apache Spark and other processing engines simultaneously with MapReduce batch jobs.
Hadoop YARN features and functions
In a cluster architecture, Apache Hadoop YARN sits between HDFS and the processing engines being used to run applications. It combines a central resource manager with containers, application coordinators and node-level agents that monitor processing operations in individual cluster nodes. YARN can dynamically allocate resources to applications as needed, a capability designed to improve resource utilization and application performance compared with MapReduce's more static allocation approach.

In addition, YARN supports multiple scheduling methods, all based on a queue format for submitting processing jobs. The default FIFO Scheduler runs applications on a first-in-first-out basis, as reflected in its name. However, that may not be optimal for clusters that are shared by multiple users. Apache Hadoop's pluggable Fair Scheduler tool instead assigns each job running at the same time its "fair share" of cluster resources, based on a weighting metric that the scheduler calculates.
Another pluggable tool, called Capacity Scheduler, enables Hadoop clusters to be run as Multi-tenant systems shared by different units in one organization or by multiple companies, with each getting guaranteed processing capacity based on individual service-level agreements. It uses hierarchical queues and subqueues to ensure that sufficient cluster resources are allocated to each user's applications before letting jobs in other queues tap into unused resources.
Hadoop YARN also includes a Reservation System feature that lets users reserve cluster resources in advance for important processing jobs to ensure they run smoothly. To avoid overloading a cluster with reservations, IT managers can limit the amount of resources that can be reserved by individual users and set automated policies to reject reservation requests that exceed the limits.
YARN Federation is another noteworthy feature that was added in Hadoop 3.0, which became generally available in December 2017. The federation capability is designed to increase the number of nodes that a single YARN implementation can support from 10,000 to multiple tens of thousands or more by using a routing layer to connect various "subclusters," each equipped with its own resource manager. The environment will function as one large cluster that can run processing jobs on any available nodes.
Key components of Hadoop YARN
In MapReduce, a JobTracker master process oversaw resource management, scheduling and monitoring of processing jobs. It created subordinate processes called TaskTrackers to run individual map and reduce tasks and report back on their progress, but most of the resource allocation and coordination work was centralized in JobTracker. That created performance bottlenecks and scalability problems as cluster sizes and the number of applications -- and associated TaskTrackers -- increased.
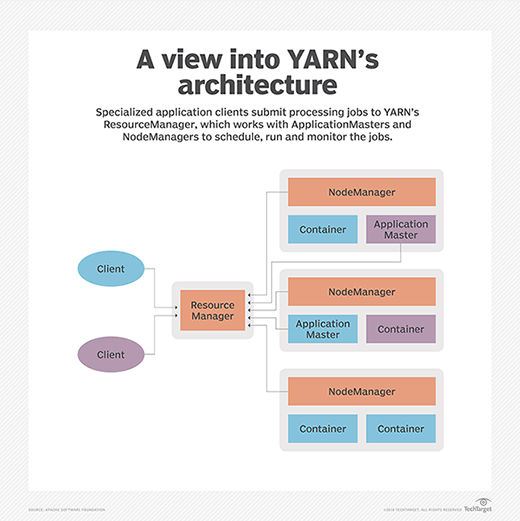
Apache Hadoop YARN decentralizes execution and monitoring of processing jobs by separating the various responsibilities into these components:
- A global ResourceManager that accepts job submissions from users, schedules the jobs and allocates resources to them
- A NodeManager slave that's installed at each node and functions as a monitoring and reporting agent of the ResourceManager
- An ApplicationMaster that's created for each application to negotiate for resources and work with the NodeManager to execute and monitor tasks
- Resource containers that are controlled by NodeManagers and assigned the system resources allocated to individual applications
YARN containers typically are set up in nodes and scheduled to execute jobs only if there are system resources available for them, but Hadoop 3.0 added support for creating "opportunistic containers" that can be queued up at NodeManagers to wait for resources to become available. The opportunistic container concept aims to optimize the use of cluster resources and, ultimately, increase overall processing throughput in Hadoop systems.
Also, while the standard approach has been to run YARN containers directly on cluster nodes, Hadoop 3.1 will include the ability to put them inside Docker containers. That would isolate applications from each other and the NodeManager's execution environment; in addition, multiple versions of applications could be run simultaneously in different Docker containers.
YARN advantages
Using Apache Hadoop YARN to separate HDFS from MapReduce made the Hadoop environment more suitable for real-time processing uses and other applications that can't wait for batch jobs to finish. Now, MapReduce is just one of many processing engines that can run Hadoop applications. It doesn't even have a lock on batch processing in Hadoop anymore: In a lot of cases, users are replacing it with Spark to get faster performance on batch applications, such as extract, transform and load jobs.
Spark can also run stream processing applications in Hadoop clusters thanks to YARN, as can technologies including Apache Flink and Apache Storm. YARN has also opened up new uses for Apache HBase, a companion database to HDFS, and for Apache Hive, Apache Drill, Apache Impala, Presto and other SQL-on-Hadoop query engines. In addition to more application and technology choices, YARN offers scalability, resource utilization, high availability and performance improvements over MapReduce.







