5V's of big data
What are the 5 V's of big data?
The 5 V's of big data -- velocity, volume, value, variety and veracity -- are the five main and innate characteristics of big data. Knowing the 5 V's lets data scientists derive more value from their data while also allowing their organizations to become more customer-centric.
Earlier this century, big data was talked about in terms of the three V's -- volume, velocity and variety. Over time, two more V's -- value and veracity -- were added to help data scientists more effectively articulate and communicate the important characteristics of big data. In some cases, there's even a sixth V term for big data -- variability.
What is big data?
Big data is a combination of unstructured, semi-structured or structured data collected by organizations. These data sets can be mined to gain insights and used in machine learning projects, predictive modeling and other advanced analytics applications.
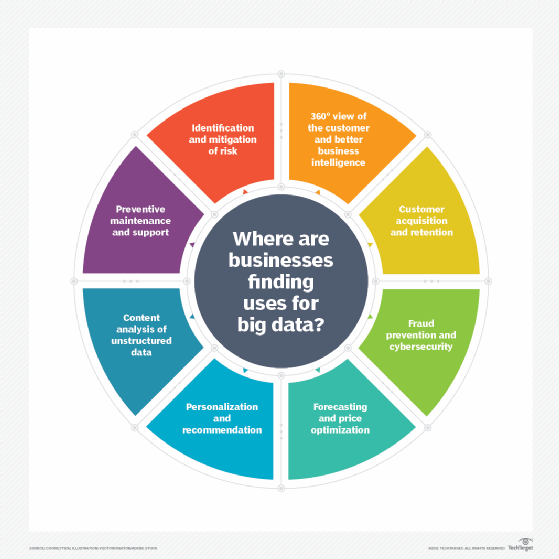
Big data can be used to improve operations, provide better customer service and create personalized marketing campaigns -- all of which can increase value for an organization. As an example, big data analytics can provide companies with valuable insights into their customers that can then be used to refine marketing techniques to increase customer engagement and conversion rates.
Big data can be used in healthcare to identify disease risk factors, or doctors can use big data to help diagnose illnesses in patients. Energy industries can use big data to track electrical grids, enact risk management or for real-time market data analysis.
Organizations that use big data have a potential competitive advantage over those that don't because they can make faster and more informed business decisions -- as provided by the data.
What are the 5 V's?
The 5 V's are defined as follows:
- Velocity is the speed at which the data is created and how fast it moves.
- Volume is the amount of data qualifying as big data.
- Value is the value the data provides.
- Variety is the diversity that exists in the types of data.
- Veracity is the data's quality and accuracy.
Velocity
Velocity refers to how quickly data is generated and how fast it moves. This is an important aspect for organizations that need their data to flow quickly, so it's available at the right times to make the best business decisions possible.
An organization that uses big data will have a large and continuous flow of data that's being created and sent to its end destination. Data could flow from sources such as machines, networks, smartphones or social media. Velocity applies to the speed at which this information arrives -- for example, how many social media posts per day are ingested -- as well as the speed at which it needs to be digested and analyzed -- often quickly and sometimes in near real time.
As an example, in healthcare, many medical devices today are designed to monitor patients and collect data. From in-hospital medical equipment to wearable devices, collected data needs to be sent to its destination and analyzed quickly.
In some cases, however, it might be better to have a limited set of collected data than to collect more data than an organization can handle -- because this can lead to slower data velocities.
Volume
Volume refers to the amount of data that exists. Volume is like the base of big data, as it's the initial size and amount of data that's collected. If the volume of data is large enough, it can be considered big data. However, what's considered to be big data is relative and will change depending on the available computing power that's on the market.
For example, a company that operates hundreds of stores across several states generates millions of transactions per day. This qualifies as big data, and the average number of total transactions per day across stores represents its volume.
Value
Value refers to the benefits that big data can provide, and it relates directly to what organizations can do with that collected data. Being able to pull value from big data is a requirement, as the value of big data increases significantly depending on the insights that can be gained from it.
Organizations can use big data tools to gather and analyze the data, but how they derive value from that data should be unique to them. Tools like Apache Hadoop can help organizations store, clean and rapidly process this massive amount of data.
A great example of big data value can be found in the gathering of individual customer data. When a company can profile its customers, it can personalize their experience in marketing and sales, improving the efficiency of contacts and garnering greater customer satisfaction.
Variety
Variety refers to the diversity of data types. An organization might obtain data from several data sources, which might vary in value. Data can come from sources in and outside an enterprise as well. The challenge in variety concerns the standardization and distribution of all data being collected.
As noted above, collected data can be unstructured, semi-structured or structured. Unstructured data is data that's unorganized and comes in different files or formats. Typically, unstructured data isn't a good fit for a mainstream relational database because it doesn't fit into conventional data models. Semi-structured data is data that hasn't been organized into a specialized repository but has associated information, such as metadata. This makes it easier to process than unstructured data. Structured data, meanwhile, is data that has been organized into a formatted repository. This means the data is made more addressable for effective data processing and analysis.
Raw data also qualifies as a data type. While raw data can fall into other categories -- structured, semi-structured or unstructured -- it's considered raw if it has received no processing at all. Most often, raw applies to data imported from other organizations or submitted or entered by users. Social media data often falls into this category.
A more specific example could be found in a company that gathers a variety of data about its customers. This can include structured data culled from transactions or unstructured social media posts and call center text. Much of this might arrive in the form of raw data, requiring cleaning before processing.
Veracity
Veracity refers to the quality, accuracy, integrity and credibility of data. Gathered data could have missing pieces, might be inaccurate or might not be able to provide real, valuable insight. Veracity, overall, refers to the level of trust there is in the collected data.
Data can sometimes become messy and difficult to use. A large amount of data can cause more confusion than insights if it's incomplete. For example, in the medical field, if data about what drugs a patient is taking is incomplete, the patient's life could be endangered.
Both value and veracity help define the quality and insights gathered from data. Thresholds for the truth of data often -- and should -- exist in an organization at the executive level, to determine whether it's suitable for high-level decision-making.
Where might a red flag appear over the veracity data? It could, for instance, be lacking in proper data lineage -- that is, a verifiable trace of its origins and movement.
The 6th V: Variability
The 5 V's above cover a lot of ground and go a long way in clarifying the proper use of big data. But there's another V worth serious consideration -- variability -- which doesn't so much define big data as it emphasizes the need to manage it well.
Variability refers to inconsistencies in either the usage or the flow of big data. In the case of the former, an organization might have more than one definition in use for particular data. For instance, an insurance company could have one department that uses one set of risk thresholds while another department uses a different set. In the second set, data that's flowing into company data stores in a decentralized fashion -- with no common entry point or upfront validation -- might find its way into different systems that modify it, resulting in conflicting sources of truth on the reporting side.
Minimizing variability in big data requires carefully constructing data flows as data moves through the organization's systems, from the transactional to the analytical and everything in between. The biggest benefit is big data veracity, as consistency in data usage yields more stable reporting and analytics and therefore higher confidence.
Learn what factors to consider when choosing between a data lake and a data warehouse to store big data.





