high-performance computing

High-performance computing (HPC) is the practice of using parallel data processing to improve computing performance and perform complex calculations. HPC achieves these goals by aggregating computing power, so even advanced applications can run efficiently, reliably and quickly as per user needs and expectations. It thus delivers much higher power and better performance than traditional computers, workstations and servers.
The need for high-performance computing (HPC)
In the modern world, groundbreaking discoveries and inventions can only happen with technology, data and advanced computing. As cutting-edge technologies like artificial intelligence (AI), machine learning (ML) and IoT evolve, they require huge amounts of data. They also need high-performance computing because HPC systems can perform quadrillions of calculations per second, compared to regular laptops or desktops that can perform at most 3 billion calculations per second (with a 3 GHz processor).
HPC is specifically needed for these reasons:
- It paves the way for new innovations in science, technology, business and academia.
- It improves processing speeds, which can be critical for many kinds of computing operations, applications and workloads.
- It helps lay the foundation for a reliable, fast IT infrastructure that can store, process and analyze massive amounts of data for various applications.
Benefits of HPC
HPC helps overcome numerous computational barriers that conventional PCs and processors typically face. The benefits of HPC are many and include the following.
High speeds
HPC is mainly about lightning-fast processing, which means HPC systems can perform massive amounts of calculations very quickly. In comparison, regular processors and computing systems would take longer -- days, weeks or even months -- to perform these same calculations.
HPC systems typically use the latest CPUs and GPUs, as well as low-latency networking fabrics and block storage devices, to improve processing speeds and computing performance.
Lower cost
Because an HPC system can process faster, applications can run faster and yield answers quickly, saving time or money. Moreover, many such systems are available in "pay as you go" modes and can scale up or down as needed, further improving their cost-effectiveness.
Reduced need for physical testing
Many modern-day applications require a lot of physical testing before they can be released for public or commercial use. Self-driven vehicles are one example. Application researchers, developers and testers can create powerful simulations using HPC systems, thus minimizing or even eliminating the need for expensive or repeated physical tests.
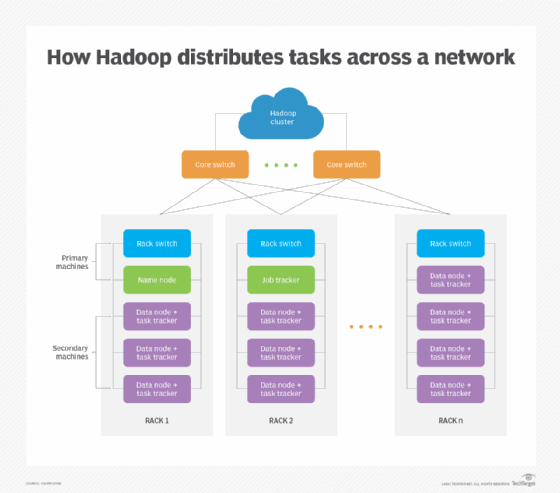
How HPC works
Most HPC systems have three main components or resources:
- Compute
- Network
- Storage
In an HPC architecture, multiple servers -- generally hundreds or thousands -- form a network or cluster. Each server is a node; and in each cluster, the nodes work in parallel to boost processing speeds and ensure HPC. Clusters are often created and removed automatically in the cloud to save time and reduce costs.
Several software programs and algorithms run simultaneously on the cluster to support multiple HPC applications. Further, the cluster is networked to the storage components to capture and store the output of these programs.
Interactions between components
It's important that these various components operate at similar speeds or performance levels. If they can't keep pace with each other, HPC cannot happen and the entire system will fail. For instance, the servers must ingest and process data efficiently from the storage components, while these components should be able to feed data quickly to servers to support HPC. Similarly, networking components should support seamless high-speed data transportation between the other components.
HPC systems can run different types of workloads. Two popular types are parallel and tightly coupled workloads.
In parallel workloads, computational problems are divided into small, independent tasks that can run in parallel at very high speeds. Often, these workloads don't communicate with each other. Examples of such workloads include risk simulations, logistics simulations, contextual search and molecular modeling.
When workloads are divided into smaller tasks and communicate continuously with each other as they perform their processing, they are said to be tightly coupled. This usually happens with workloads across different nodes in a cluster. Some common examples of tightly coupled workloads are automobile collision emulations, geospatial simulations, weather forecast modeling and traffic management.
Both kinds of workloads require high processing speeds and accurate output, for which HPC is required.

Applications of HPC
HPC is used in many real-life scenarios to solve complex problems in science, business and engineering. Some academic institutions also use HPC systems. Some government agencies, particularly the military, rely on HPC for complex applications. As the demand for processing power and speed grows for real-world applications, HPC will likely interest businesses of all sizes, particularly for transaction processing, and data warehouses.
HPC systems are also used in many other industries, including but not limited to the following:
- Manufacturing. To design, manufacture and test new products using simulations.
- Healthcare. To research and develop new vaccines, drugs and treatments for diseases; improve screening techniques; and to make more accurate patient diagnoses.
- Media and entertainment. To create animations and special effects, transcode media files, support high-speed video and live event streaming and create immersive entertainment using augmented reality
- Aerospace. For personnel training and to create critical simulations for airplane testing.
- Oil and gas. To test reservoir models, locate oil and gas resources, perform spatial analyses and conduct fluid flow and seismic processing simulations.
- Automotive. To simulate crash tests in the automotive industry, which are less expensive than physical tests.
- Financial services. To automate trading, detect credit card fraud and track real-time stock trends.
- Meteorology. To predict and track storms and other unusual weather patterns.
A supercomputer is one of the best-known examples of HPC, in which one large computer is made up of many computers and processors that work together to achieve parallel processing and high performance.
Challenges involved in HPC deployments
Although HPC has progressed massively in recent decades, some barriers remain that hinder widespread HPC adoption:
- Setup capital. Setting up the environment for HPC involves significant investments that small companies usually cannot afford.
- Ongoing costs. Ongoing management and other operational costs can be a big barrier.
- Aging on-premises infrastructure. As on-premises equipment ages, it could reduce the performance of HPC.
- Need for frequent upgrades. HPC systems must be continually upgraded to maintain their performance levels. Postponing these upgrades could affect efficiency and lengthen processing times.
Many of these barriers exist due to the on-premises deployment of HPC systems. Cloud technologies that are specifically architected for HPC workloads -- and offer extensive capacity and a "pay as you go" option -- could be a feasible solution to these challenges.
See a comprehensive guide to HPC in the data center, how HPC services bring computational power to more organizations and ways to maximize HPC applications' performance. Also, explore how to implement GPUs for high-performance computing and learn about high-performance computing as a service.






