Most in-demand data science skills include ML, Python
Experts detail the skills employers want most in data scientists -- notably machine learning and programming languages -- and why often the most valuable expertise comes with time.
As the role of data scientist grows in magnitude, it's more important than ever to stay current on today's most in-demand data science skills. But it's not just the programming and mathematical skills that data scientists need to hone; domain and business knowledge is equally valuable.
The top tech skills employers look for most in data scientists are machine learning and expertise in Python, R, SQL and Hadoop, according to research results published in April 2019 by Indeed, one of the top jobs sites.
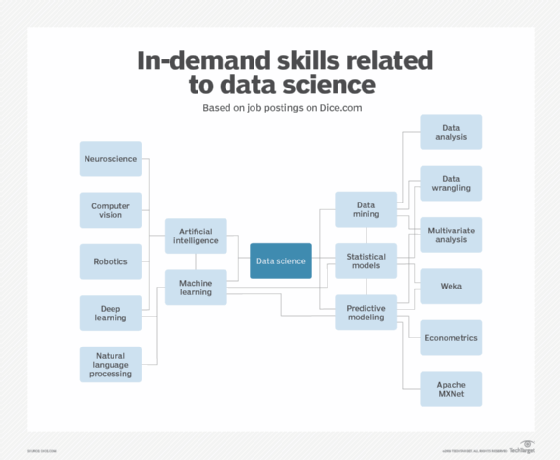
Similarly, employers looking to fill data science-related roles seek candidates skilled in artificial intelligence, machine learning, data mining, predictive analytics and statistical models, according to technology job site Dice, which supplied research data to SearchBusinessAnalytics.
On top of those technical in-demand data science skills, data scientists should also be skilled communicators who are familiar with the full lifecycle of their projects and the business context of their work, said Forrester analyst Kjell Carlsson.
"No data scientist can be an expert at all aspects of these, but every data scientist needs an understanding of each," said Carlsson.
Demand for data scientists started spiking in 2013 and has grown every year since, according to Dice. Meanwhile, the number of data scientist job postings on Indeed has increased by 256% since December 2013. The supply of skilled data science applicants, however, is growing at a slower pace.
Core data science skills
The two core skills demanded of any data scientist are computer programming and data analysis, said Andrew Flowers, an economist at Indeed.
No data scientist can be an expert at all aspects of these, but every data scientist needs an understanding of each.
Kjell CarlssonAnalyst, Forrester
For programming, the two languages most used by data scientists are Python and R, Flowers said. Python is one of the fastest-growing programming languages, according to the Indeed report on in-demand data science skills. In 2018, the job site reported that Python searches were up 26% year-over-year, while R searches declined 8% year-over-year.
Secondary tools such as SQL for querying databases, Git for version control, and Hadoop or Spark for cluster-computing are also important in programming, as is being fluent in software engineering best practices, Flowers added.
Skills that fall under the second core skill, data analysis, include routine statistical tests for "teasing out causal inference," using machine learning algorithms for prediction and methods in natural language processing and data visualization, Flowers said.
Machine learning skills
With so many companies adopting a data-driven and AI-centric business approach, machine learning skills become particularly imperative.
Pedro Alves Nogueira, director of engineering and head of artificial intelligence and data science at freelancing platform Toptal, said he considers machine learning as a set of skills as opposed to a skill in itself.
"In some cases, listing machine learning as a singular skill is a sign that the hiring company doesn't have a clear focus on what they need from the data scientist," Nogueira said. "It can also hint at the need for someone more senior that has the capability of helping them structure their data analysis efforts."
Meanwhile, Carlsson said data scientists need to understand several machine learning methods, including linear and logistic regression, tree models and ensembles like Random Forest and GBM and, going forward, neural networks.
A visual of the most sought after skills related to data science based on job posting data from Dice.com.
Veteran data scientists may have an advantage
Machine learning and other in-demand data science skills are certainly central, but they focus on programming and mathematical aptitude, said Ryohei Fujimaki, founder and CEO of dotData, a data science and machine learning platform vendor. Equally or even more important is the expertise that comes with time and experience.
"Domain knowledge relevant to a specific business area is a key enabler for data science technologies to deliver business value," Fujimaki said. "Business knowledge is also required for problem definition and result validation."
Without domain or business knowledge, it's hard to deliver data science projects with value. That's because data scientists can't acquire that knowledge in a short time or from schooling alone.
"While the skills themselves are relatively easy to learn for any solid developer, the required domain knowledge, intuition and overall experience using the appropriate models and tools is something that cannot be easily learned in traditional boot camps or online courses," Nogueira said. "They require deeper training on mathematics, statistics and computer science that takes years to complete, followed by domain experience that cannot be conveyed in a matter of months but rather years."
The gap between new and existing data science talent will take several years to fully bridge, he said. So enterprises should focus on investing in existing talent and employees with domain or theoretical knowledge, and make sure that employees perfect their artificial intelligence and data science skills, he added.