containers (container-based virtualization or containerization)

What are containers (container-based virtualization or containerization)?
Containers are a type of software that can virtually package and isolate applications for deployment. Containers package an application's code and dependencies together, letting the application reliably run in all computing environments.
Containers share access to an operating system (OS) kernel without the traditional need for virtual machines (VMs). Containers can be used to run small microservices, larger applications or even lightweight container OSes.
Container technology has its roots in partitioning, dating back to the 1960s, and chroot process isolation developed as part of Unix in the 1970s. Its modern form is expressed in application containerization, such as Docker, and system containerization, such as LXC, part of the Linux Containers Project. Both container styles let an IT team abstract application code from the underlying infrastructure, which simplifies version management and enables portability across various deployment environments.
Developers use containers for development and test environments. IT operations teams might deploy live production IT environments on containers, which can run on bare-metal servers, VMs and the cloud.
How containers work
Containers hold the components necessary to run desired software. These components include files, environment variables, dependencies and libraries. The host OS limits the container's access to physical resources, such as CPU, storage and memory, so a single container can't consume all of a host's physical resources.
Container image files are complete, static and executable versions of an application or service that differ from one technology to another. Docker images, for example, are made up of multiple layers. The first layer, the base image, includes all the dependencies needed to execute code in a container. Each image has a readable/writable layer on top of static unchanging layers. Because each container has its own specific container layer that customizes that specific container, underlying image layers can be saved and reused in multiple containers. Likewise, multiple instances of an image can run in a container simultaneously, and new instances can replace failed ones without disrupting the application's operation.
An Open Container Initiative (OCI) image is made up of a manifest, file system layers and configurations. An OCI image has two specifications to operate: a runtime and an image specification. Runtime specifications outline the functioning of a file system bundle, which are files containing all necessary data for performance and runtimes. The image specification contains the information needed to launch an application or service in the OCI container.
The container engine executes images, and many organizations use a container scheduler and orchestration technology, such as Kubernetes, to manage deployments. Containers have high portability because each image includes the dependencies needed to execute the code. For example, container users can execute the same image on an Amazon Web Services (AWS) cloud instance during a test, then an on-premises Dell server for production without changing the application code in the container.
Containers vs. VMs
Virtualization is the creation of a virtual version of something, such as an OS or server. Virtualization simulates hardware functionality to create a virtual system abstracted from a host system. This process can be used to operate multiple OSes, more than one virtual system and various applications on a single server, for example.
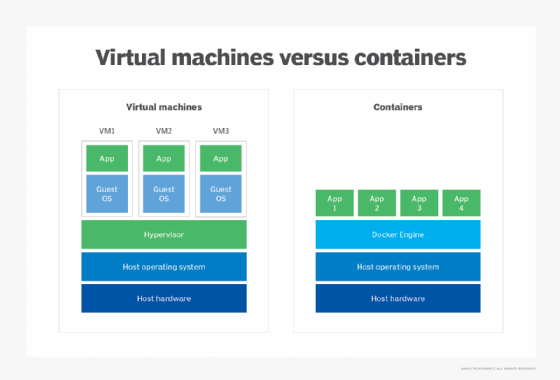
Although they share some basic similarities, containers and virtualization differ in that a virtualized architecture emulates a hardware system. A software layer, called a hypervisor, is used in virtualization to emulate hardware from pooled CPUs, memory, storage and network resources, which can be shared numerous times by multiple instances of VMs.
VMs can require substantial resource overhead, such as memory, disk and network input/output, because each VM runs a guest OS. This means VMs can be large and take longer to create than containers.
Because containers share the OS kernel, one instance of an OS can run many isolated containers. The OS supporting containers can also be smaller, with fewer features, than an OS for a VM.
As opposed to virtualizing the underlying hardware, containers virtualize the OS so each individual container holds only the application, its libraries and dependencies. Containers are lightweight compared to VMs, as containers don't require the use of a guest OS.
Application containers and system containers
Application containers, such as Docker, encapsulate the files, dependencies and libraries of an application to run on an OS. Application containers let the user create and run a separate container for multiple independent applications or multiple services that constitute a single application. For example, an application container would be well-suited for a microservices application, where each service that makes up the application runs independently from one another.
System containers, such as LXC, are technologically similar to both application containers and to VMs. A system container can run an OS, like how an OS would run encapsulated on a VM. However, system containers don't emulate the hardware of a system. Instead, they operate similarly to application containers, and a user can install different libraries, languages and system databases.
Benefits of containers
Containers offer the following benefits:
- Efficiency. Because containers share the same OS kernel as the host, they're more efficient than VMs, which require separate OS instances.
- Portability. Containers have better portability than other application hosting technologies. They can move among any systems that share the host OS type without requiring code changes. This encapsulation of the application operating code in the container means there are no guest OS environment variables or library dependencies to manage.
- Memory, CPU and storage gains. Proponents of containerization point to gains in efficiency for memory, CPU and storage as key benefits of this approach compared with traditional virtualization. Because containers don't have the overhead required by VMs, such as separate OS instances, it's possible to support many more containers on the same infrastructure. An average physical host could support dozens of VMs or hundreds of containers. However, in actual operations, the host, container and VM sizes are highly variable and subject to the demands of a specific application or applications.
- Consistency. Containers are consistent throughout the application lifecycle. This fosters an agile environment and facilitates new approaches, such as continuous integration and continuous delivery (CI/CD). They also spin up faster than VMs, which is important for distributed applications.
Disadvantages of containers
Containers have the following drawbacks:
- Lack of isolation. A potential drawback of containerization is the lack of isolation from the host OS. Because containers share a host OS, security threats have easier access to the entire system when compared with hypervisor-based virtualization. One approach to addressing this security concern has been to create containers from within an OS running on a VM. This approach ensures that, if a security breach occurs at the container level, the attacker can only gain access to that VM's OS, not other VMs or the physical host.
- Lack of OS flexibility. In typical deployments, each container must use the same OS as the base OS, whereas hypervisor instances have more flexibility. For example, a container created on a Linux-based host could not run an instance of the Windows Server OS or applications designed to run on Windows Server.
- Difficulty monitoring visibility. With up to hundreds or more containers running on a server, it might be difficult to see what's happening in each container.
Various technologies from container and other vendors as well as open source projects are available and under development to address the operational challenges of containers. They include security tracking systems, monitoring systems based on log data as well as orchestrators and schedulers that oversee operations.
Common container uses
Containers are frequently paired with microservices and the cloud but offer benefits to monolithic applications and on-premises data centers as well.
Containers are well-adapted to work with microservices. Each service that makes up the application is packaged in an independently scalable container. For example, a microservices application can be composed of containerized services that generate alerts, log data, handle user identification and provide many other services.
Each service operates on the same OS while staying individually isolated. Each service can scale up and down to respond to demand. Cloud infrastructure is designed for elastic, unlimited scaling.
Traditional monolithic application architectures are designed so that all the code in a program is written in a single executable file. Monolithic applications don't readily scale in the way that distributed applications do, but they can be containerized. For example, the Docker Modernize Traditional Applications program helps users transition monolithic applications to Docker containers as is, with adaptations for better scaling, or via a full rebuild and rearchitecting.
Containers are also used to run applications in different environments. Because all of an application's code and dependencies are included in the container, developers can lift and shift the application without needing to redesign it to work in a new environment. If changes do need to be made, then containerized applications might only need to go through code refactoring, where only small segments of the code need to be restructured.
Container tool and platform providers
Numerous vendors offer container platforms and container management tools, such as cloud services and orchestrators. Docker and Kubernetes are well-known product names in the container technology space, and the technologies underpin many other products.
- Docker is an open source application container platform designed for Linux and, more recently, Windows, Apple and mainframe OSes. Docker uses resource isolation features, such as cgroups and Linux kernels, to create isolated containers. Docker is an eponymous company formed to sell enterprise-supported container hosting and management products. In November 2019, the company sold the Docker Enterprise business to Mirantis.
- The open source container orchestrator Kubernetes, created by Google, has become the de facto standard for container orchestration. It organizes containers into pods on nodes, which are the hosting resources. Kubernetes can automate, deploy, scale, maintain and otherwise operate application containers. A plethora of products are based on Kubernetes with added features and or support, such as Rancher, acquired by SUSE in December 2020; Red Hat OpenShift; and Platform9.
- Microsoft offers containerization technologies, including Hyper-V and Windows Server containers. Both types are created, maintained and operated similarly, as they use the same container images. However, the services differ in terms of the level of isolation. Isolation in Windows Server containers is achieved through namespaces, resource control and other techniques. Hyper-V containers provide isolation through the container instances running inside a lightweight VM, which makes the product more of a system container.
- Amazon Elastic Container Service (ECS) is a cloud computing service in AWS that manages containers and lets developers run applications in the cloud without having to configure an environment for the code to run in. Amazon ECS launches containers through AWS Fargate or Amazon Elastic Compute Cloud. Its features include scheduling, Docker integration, container deployments, container auto-recovery and container security.
Besides these, other container orchestration tools are also available, such as DC/OS from D2iQ -- formerly Mesosphere -- and LXC.
The major cloud vendors all offer diverse containers as a service products as well, including Amazon ECS and Amazon Elastic Kubernetes Service, Google Kubernetes Engine, Microsoft Azure Container Instances, Azure Kubernetes Service and IBM Cloud Kubernetes Service. Containers can also be deployed on public or private cloud infrastructure without the use of dedicated container products from the cloud vendor.
Future of containers
Enterprises have gradually increased their production deployment of container software beyond application development and testing. For most organizations, their focus has shifted to container orchestration and especially Kubernetes, which most vendors now support. As organizations consolidate their processes and toolsets for IT operations, they want more granular control to monitor and secure what's inside containers.
The adoption of container software has expanded across various areas of IT -- from security to networking to storage. Some organizations have deployed stateful applications, such as databases and machine learning (ML) apps on containers and Kubernetes, to ensure consistent management. For example, containerized ML doesn't slow down a machine as much compared to containerless ML, and it doesn't take up as many resources over time.
Some organizations use containers as a part of a broader Agile or DevOps transformations. One example includes containerizing microservices in a CI/CD environment. Another potential use is to proliferate the use of containers and Kubernetes out to the network edge, to remotely deploy and manage software in various locations and on a variety of devices.
It's unlikely that containers will replace server virtualization, as both technologies are complementary to one another. As containers are run in lightweight environments and VMs take more resources, hardware virtualization makes it easier to manage the infrastructure needed for containers.
In addition to the acquisitions noted above, other major vendors have acquired smaller startups to bolster their toolchain offerings. For example, Cisco acquired Portshift -- now Panoptica -- in October 2020, and Red Hat acquired StackRox in January 2021.
Gartner predicts that by 2024, 15% of all enterprise applications will run in a container environment. This is a more than 10% increase since 2020.
Learn more about the history, evolution and future of containers.





