8 proactive steps to improve data quality
Here are eight steps to take to improve your organization's data quality in a proactive way, before data errors and other issues cause business problems.

Establishing and maintaining high levels of data quality is a constant challenge for organizations -- and the unbridled growth in the amounts of data they're generating makes that task more difficult. The use of data to help uncover new business insights and drive effective decision-making is also increasing at a rapid pace. As a result, IT and data management teams are contending with more data that is more important to their organization.
A reactive approach to data quality improvement is like firefighting: We respond to data quality issues after they occur, jumping from one crisis to another. The biggest issues get the most attention, and the overall number of them often continues to escalate. On the other hand, a proactive program to improve data quality aims to avoid data errors and other issues and to identify ones that do occur before they become a problem.
Doing so ensures that data-driven decisions are based on good information. It also supports the broader objectives of data governance programs, which often incorporate data quality efforts.
What is data quality?
Name a technology, architecture, product or best practice and you'll find lively debates occurring between its proponents and critics. But one thing that everybody in IT agrees on is the adage garbage in, garbage out, or GIGO. It succinctly states the informal rule that the quality of the information produced by a computer process depends on the quality of the data it uses. If incorrect data is input, the output will also be incorrect.
That's why good data quality is so important to organizations. Data quality measures the condition of data elements to identify issues and assess their overall "level of truth." That enables an organization to judge whether data is fit for its intended purpose and can be relied on for decision-making.
IT and data management teams use a varying number of dimensions to measure data quality, but the following are the most common ones:
- Accuracy. Does the data correctly describe the real-world object or event to which it pertains?
- Completeness. Does the data contain all of the attributes needed to provide a full and accurate description of the object or event?
- Consistency. Is a particular data element the same across different systems and data stores in an organization?
- Timeliness. Is the data up to date and available for use when it's needed?
- Conformity. Does the data conform to the organization's documented set of business definitions and specifications, including standards on data type, size and format?
- Integrity. Can a data element's relationship with others it is connected to across the enterprise be traced to ensure that all of the information is reliable?
- Uniqueness. Does a record pertaining to an object or event appear only once in a data set, or are there duplicate entries?
What causes data quality problems?
There are myriad reasons for data quality issues -- for example, manual data entry errors and software programming mistakes. When incorrect data is discovered, data quality specialists or other data and analytics professionals will identify and correct the issues through steps such as data profiling and data cleansing. The data quality team also recommends corrective measures to make sure the same problems don't reoccur in the future.
But systemic weaknesses that result in enterprise-wide data quality issues are much more challenging to resolve. During my career, I've identified the following set of common root causes that contribute to organizational problems on data quality and hamper efforts to improve it:
Not treating data as an enterprise asset. Despite all of the articles, reports and academic papers on the intrinsic business value of data, there are organizations that continue to underestimate its importance. As a consultant, I've found that many of these organizations are relatively new, small in size and still in the process of growing their IT environment. As a result, they've yet to build the support infrastructure of people, processes and products that they need to effectively manage and govern data, including a concerted effort to track and improve data quality.
A lack of buy-in from upper management on the importance of data quality. Although this is becoming rarer, some senior management teams still aren't convinced that the expenditures required to ensure high-quality data are warranted. As we'll see later, organizations can achieve good data quality on a tight technology budget. But even then, management needs to allocate personnel to data quality initiatives, which it may be reluctant to do if it isn't sold on the need for such work.
IT teams not having the time to fully implement and monitor data quality best practices. Instead of focusing on transforming data into trustworthy insights, many organizations are drowning in their data. From data creation and initial storage to data preparation, analysis, presentation and ongoing governance, the IT team is unable to contend with quality issues in the rapidly growing data volumes. Even if the appropriate data governance infrastructure and processes are in place, team members may be forced to triage new data sets when they apply data quality measures.
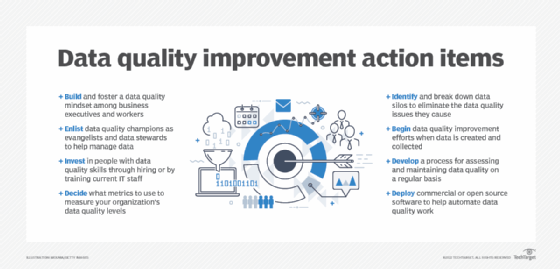
How to improve data quality in a proactive way
Whether an organization has a two-person IT team or a 20,000-person one, data is indeed an enterprise asset. The only difference is the size of the program for ensuring that data quality is at a sufficiently high level. That isn't an easy task. Most data elements don't sit idle -- they find their way into multiple data stores and applications. An incorrect data value is like a virus: Once created, it will spread into reports, dashboards, spreadsheets and other analytics tools across the organization.
Here's a list of eight recommendations for building a proactive data quality improvement program that will ease the challenges. It is by no means all-inclusive but will help you begin thinking about -- and get started on -- the process of improving data quality.
1. Build and foster a data quality mindset in your organization
As with all enterprise-wide initiatives, creating an internal mindset around data quality improvement begins at the top of the org chart. Getting upper management buy-in is critical, as noted above. Market the benefits of better data quality to senior executives to get their support, and also to business managers and users. The idea is to integrate data quality into the organizational fabric so it isn't just seen as an IT initiative.
2. Enlist data quality champions and data stewards
In connection with the first step, internal champions for a data quality program can help to evangelize its benefits. Data quality champions should come from all levels of the organization, from the C-suite to operational workers. It's important to have champions in positions that are relatable to the audience you want to influence. A data entry manager who is a proponent of data quality best practices will have a much greater impact on other end users than the chief data officer would.
As part of a data governance program, data stewards work closely with the data under their control and have a strong understanding of its business meaning and how it's used. Depending on the data, stewards can be from either the business or IT. A data steward is often responsible for evaluating data quality on a regular basis, in addition to duties such as educating others about the data, ensuring that it's used properly and helping to develop new data standards and guidelines.
3. Invest in people with the right skills, through training if necessary
Skilled data quality specialists are hard to find and can be expensive to hire. But if that's an issue, it doesn't prevent you from "growing your own." Look inside your organization for IT and data management personnel who are interested in the job; then, give them the time and training they need to learn the science of data quality and the tasks and techniques it involves. Build the training program based on your budgetary constraints and the people you have available to help.
4. Decide what metrics to use to measure your data quality
As mentioned above, there are several different dimensions that can be used to measure data quality levels. Data quality specialists and other IT staffers need to work with business managers and users upfront to identify and document the metrics they will use during the process of analyzing data sets and evaluating the progress of data quality improvement efforts.
You'll have to continue to be proactive on this, too. Both the analysis procedures and data quality metrics for a data set may need to be adjusted over time. Before using particular KPIs and other metrics in future evaluations, data quality specialists will need to verify that they're still applicable. In addition, the processes and metrics successfully used during some evaluations may not be universally applicable to all of an organization's data sets.
5. Identify and break down data silos
A data silo is a repository of data that isn't effectively shared across an organization and may not be properly managed. Although some entities know the data exists, other departments, business units or workgroups are unaware of its availability and unable to access and use it; the IT team may also not be aware of siloed data. From Excel spreadsheets and Access databases to larger data stores, organizations are often unpleasantly surprised to discover how many data silos they have.
Although data silos have the potential to cause a wide range of problems, the following are the most common ones:
- Data errors that don't get fixed. A lack of oversight by IT may result in poor data quality that leads to faulty business decisions.
- Duplicate data that's inconsistent. If similar data sets aren't in harmony, there isn't a single source of truth to rely on for sound decision-making.
- Lost opportunities for data sharing. The organization can't take advantage of siloed data's potential value across the enterprise. Even when data sharing does occur, it's often inconsistent and disjointed.
The duties of data quality specialists include identifying data silos and working to eliminate them to help improve the quality of data overall. You may find that some business units or teams responsible for data silos have concerns about losing ownership of their data. In such cases, breaking down silos will be much easier if you promote the benefits of enterprise data quality and data governance, instead of just dictating and enforcing rules against them.
6. Begin data quality efforts when data is created and collected
To produce high-quality data sets, an organization must follow internally defined best practices during the data creation process or the acquisition of data from external sources. That applies to conventional transaction data and sets of big data that may include a combination of structured, unstructured and semistructured data. Data management and governance teams should meet with end users to document how they use data and identify business policies and requirements related to the data. Then you can work to develop standard data definitions and data entry and formatting rules.
Most databases provide a robust set of constraints to enforce data conformity, which can help with data quality. For non-database platforms that enforce it programmatically, investigate other mechanisms to store common code and data quality rules. I also highly recommend that organizations of all sizes evaluate master data management (MDM) platforms and data governance software suites. Their framework of procedures and tools can become part of the foundation of your data quality program and help you to more quickly establish and then maintain a single source of truth in data sets enterprise-wide.
7. Develop a process to regularly assess and maintain data quality
In new systems and mature IT environments alike, performing periodic data quality reviews throughout the entire data lifecycle helps organizations prevent incorrect or incomplete data from affecting business processes and operations.
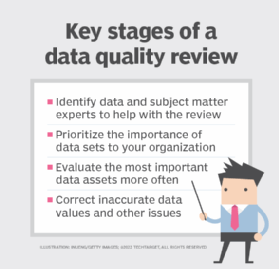
When application development teams address data quality issues early on, the amount of rework required to correct them is far less than if they're found during a later lifecycle stage. As data matures, though, it's important to evaluate it regularly to make sure that it continues to fulfill its intended purpose and remains reliable for decision-making.
That means proactive data quality checks should be a core component of your quality improvement program, using the following approach:
- Identify the data and subject matter experts who can help with the reviews.
- Prioritize the importance of different data sets to the organization.
- Evaluate the most important data assets more frequently than lower-priority ones.
- Correct inaccurate data values and other issues found during a review.
When you do find data quality problems, your goals should include determining the severity and scope of their business impact and identifying their root cause so that can also be addressed.
8. Deploy tools to help manage data quality -- no money, no problem
Numerous data quality software tools are available to assist you in your data quality analysis and data cleansing efforts, including commercial products from Ataccama, IBM, Informatica, Oracle, Precisely, SAP, SAS, Talend, Tibco Software and many other vendors. Resources like the user reviews on Gartner's Peer Insights platform can help you compare the competing product offerings.
Don't have enough funds to invest in data quality tools, as well as data governance software and MDM products? That's certainly a challenge, but not an excuse. If the organizational desire is there, you can still create a robust, proactive data quality improvement program. I've reviewed several startup ones that used a patchwork of documents, procedures, process libraries and open source technologies. Several open source data quality tools can be downloaded and used for free, such as DataCleaner, OpenRefine, osDQ and Talend's community edition.
Uses and benefits of high-quality data
When you analyze IT processes at a macro level, you find that regardless of the technologies, applications and other products deployed, there's one commonality to all successful computing environments: high-quality data. On the other hand, bad data adds both IT and business costs, especially when data quality issues aren't caught quickly.
In 1992, professors George Labovitz and Yu Sang Chang coined the 1-10-100 rule to help visualize the cost impact of quality management shortcomings in general. Applied in a data quality context, the widely cited rule holds that it costs organizations:
- $1 to prevent bad data from occurring;
- $10 to correct bad data that gets created; and
- $100 if they fail to correct bad data.
Labovitz and Chang didn't intend for the rule to be used in specific cost calculations; their intent was to help executives easily understand why a proactive approach to quality management -- including data quality improvement -- is much more cost-effective than dealing with defects after they cause a problem.
In addition to the direct monetary costs associated with poor data quality, other negative effects -- such as loss of customer goodwill, damage to the organization's reputation and flawed business strategies -- are much harder to quantify but no less real.
Organizations should view the cost of a proactive data quality initiative as an investment that leads to better decision-making, improved operational efficiency and stronger customer service. Such benefits give businesses a competitive advantage over rivals that aren't able to act on the insights provided by high-quality data.
Your organization will also benefit from fewer data quality issues and a reduction in firefighting activities. And the good news is that it's never too late to build a successful data quality program.







