Static SQL vs. dynamic SQL for database application performance
Learn the difference between static SQL vs. dynamic SQL and the benefits and drawbacks of each for database application performance. Get a definition of stored procedure, find out about database drivers and wire protocol database drivers and how the network affects database performance.
 |
|
In this excerpt from The Data Access Handbook learn the advantages and disadvantages of static SQL and dynamic SQL for database application performance, get a definition of stored procedure and find out how the network affects database performance. You'll also learn how the database driver can muddle database performance and the benefits of using a wire protocol database driver.
Table of Contents
![]() Designing for performance: Strategic database application deployments
Designing for performance: Strategic database application deployments
![]() An introduction to database transaction management
An introduction to database transaction management
![]() Executing SQL statements using prepared statements and statement pooling
Executing SQL statements using prepared statements and statement pooling
![]() Database access security: network authentication or data encryption?
Database access security: network authentication or data encryption?
![]() Static SQL vs. dynamic SQL for database application performance
Static SQL vs. dynamic SQL for database application performance

Static SQL Versus Dynamic SQL
At the inception of relational database systems and into the 1980s, the only portable interface for applications was embedded SQL. At that time, there was no common function API such as a standards-based database API, for example, ODBC. Embedded SQL is SQL statements written within an application programming language such as C. These statements are preprocessed by a SQL preprocessor, which is database dependent, before the application is compiled. In the preprocessing stage, the database creates the access plan for each SQL statement. During this time, the SQL was embedded and, typically, always static.
In the 1990s, the first portable database API for SQL was defined by the SQL Access Group. Following this specification came the ODBC specification from Microsoft. The ODBC specification was widely adopted, and it quickly became the de facto standard for SQL APIs. Using ODBC, SQL did not have to be embedded into the application programming language, and precompilation was no longer required, which allowed database independence. Using SQL APIs, the SQL is not embedded; it is dynamic.
What is static SQL and dynamic SQL? Static SQL is SQL statements in an application that do not change at runtime and, therefore, can be hard-coded into the application. Dynamic SQL is SQL statements that are constructed at runtime; for example, the application may allow users to enter their own queries. Thus, the SQL statements cannot be hard-coded into the application.
Static SQL provides performance advantages over dynamic SQL because static SQL is preprocessed, which means the statements are parsed, validated, and optimized only once.
If you are using a standards-based API, such as ODBC, to develop your application, static SQL is probably not an option for you. However, you can achieve a similar level of performance by using either statement pooling or stored procedures. See "Statement Pooling," page 29, for a discussion about how statement pooling can improve performance.
A stored procedure is a set of SQL statements (a subroutine) available to applications accessing a relational database system. Stored procedures are physically stored in the database. The SQL statements you define in a stored procedure are parsed, validated, and optimized only once, as with static SQL.
Stored procedures are database dependent because each relational database system implements stored procedures in a proprietary way. Therefore, if you want your application to be database independent, think twice before using stored procedures.
The Network
The network, which is a component of the database middleware, has many factors that affect performance: database protocol packets, network packets, network hops, network contention, and packet fragmentation. See "Network," in Chapter 4 (page 86) for details on how to understand the performance implications of the network and guidelines for dealing with them.
In this section, let's look at one important fact about performance and the network: database application performance improves when communication between the database driver and the database is optimized.
With this in mind, you should always ask yourself: How can I reduce the information that is communicated between the driver and the database? One important factor in this optimization is the size of database protocol packets.
The size of database protocol packets sent by the database driver to the database server must be equal to or less than the maximum database protocol packet size allowed by the database server. If the database server accepts a maximum packet size of 64KB, the database driver must send packets of 64KB or less. Typically, the larger the packet size, the better the performance, because fewer packets are needed to communicate between the driver and the database. Fewer packets means fewer network round trips to and from the database.
For example, if the database driver uses a packet size of 32KB and the database server's packet size is configured for 64KB, the database server must limit its packet size to the smaller 32KB packet size used by the driver—increasing the number of packets sent over the network to return the same amount of data to the client (as shown in Figure 2-14).
Figure 2-14 Using different packet sizes
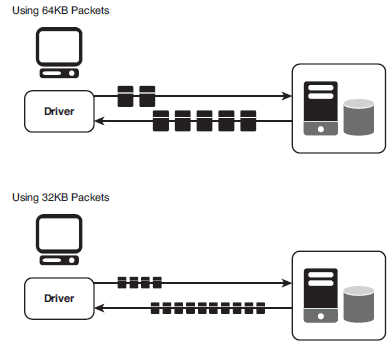
This increase in the number of packets also means an increase in packet overhead. High packet overhead reduces throughput, or the amount of data that is transferred from sender to receiver over a period of time.
You might be thinking, "But how can I do anything about the size of database protocol packets?"You can use a database driver that allows you to configure their size. See "Runtime Performance Tuning Options," page 62, for more information about which performance tuning options to look for in a database driver.
The Database Driver
The database driver, which is a component of the database middleware, can degrade the performance of your database application because of the following reasons:
- The architecture of the driver is not optimal.
- The driver is not tunable. It does not have runtime performance tuning options that allow you to configure the driver for optimal performance.
See Chapter 3, "Database Middleware: Why It's Important," for a detailed description of how a database driver can improve the performance of your database application.
In this section, let's look at one important fact about performance and a database driver: The architecture of your database driver matters. Typically, the most optimal architecture is database wire protocol.
Database wire protocol drivers communicate with the database directly, eliminating the need for the database's client software, as shown in Figure 2-15.
Figure 2-15 Database wire protocol architecture
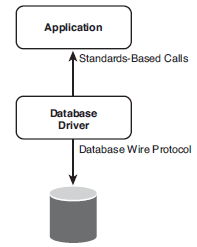
Using a wire protocol database driver improves the performance of your database application because it does the following:
- Decreases latency by eliminating the processing required in the client software and the extra network traffic caused by the client software.
- Reduces network bandwidth requirements from extra transmissions. That is, database wire protocol drivers optimize network traffic because they can control interaction with TCP.
We go into more detail about the benefits of using a database wire protocol driver in "Database Driver Architecture," page 55.
Know Your Database System
You may think your database system supports all the functionality that is specified in the standards-based APIs (such as ODBC, JDBC, and ADO.NET). That is likely not true. Yet, the driver you use may provide the functionality, which is often a benefit to you. For example, if your application performs bulk inserts or updates, you can improve performance by using arrays of parameters. Yet, not all database systems support arrays of parameters. In any case, if you use a database driver that supports them, you can use this functionality even if the database system does not support it, which 1) results in performance improvements for bulk inserts or updates, and 2) eliminates the need for you to implement the functionality yourself.
The trade-off of using functionality that is not natively supported by your database system is that emulated functionality can increase CPU use. You must weigh this trade-off against the benefit of having the functionality in your application.
The protocol of your database system is another important implementation detail that you should understand. Throughout this chapter, we discussed design decisions that are affected by the protocol used by your database system of choice: cursor-based or streaming. Explanations of these two protocols can be found in "One Connection for Multiple Statements" on page 16.
Table 2-3 lists some common functionality and whether it is natively supported by five major database systems.
Table 2-3 Database System Native Support
| Functionality | DB2 | Microsoft SQL Server | MySQL | Oracle | Sybase ASE |
| Cursor-based protocol | Supported |







