Hadoop vs. Spark: An in-depth big data framework comparison
Hadoop and Spark are widely used big data frameworks. Here's a look at their features and capabilities and the key differences between the two technologies.

Hadoop and Spark are two of the most popular data processing frameworks for big data architectures. They're both at the center of a rich ecosystem of open source technologies for processing, managing and analyzing sets of big data. As a result, organizations commonly evaluate both of them for potential use in applications.
Most debates on using Hadoop vs. Spark revolve around optimizing big data environments for batch processing or real-time processing. But that oversimplifies the differences between the two frameworks, formally known as Apache Hadoop and Apache Spark. While Hadoop initially was limited to batch applications, it -- or at least some of its components -- can now also be used in interactive querying and real-time analytics workloads. Spark, meanwhile, was first developed to process batch jobs more quickly than was possible with Hadoop.
Also, it isn't necessarily an either-or choice. Many organizations run both platforms for different big data use cases. They can be used together, too: Spark applications are often built on top of Hadoop's YARN resource management technology and the Hadoop Distributed File System (HDFS). HDFS is one of the main data storage options for Spark, which doesn't have its own file system or repository.
Here's a close look at the components, features and capabilities of Hadoop and Spark and how they differ, starting with some basic details about each open source framework.
What is Hadoop?
First released in 2006, Hadoop was created by software engineers Doug Cutting and Mike Cafarella to process large amounts of data, initially using its namesake file system and MapReduce, a programming model and processing engine that Google promoted in a 2004 technical paper. Hadoop provides a way to efficiently break up large data processing problems across different computers, run computations locally and then combine the results. The framework's distributed processing architecture makes it easy to build big data applications for clusters containing hundreds or thousands of commodity servers, called nodes.
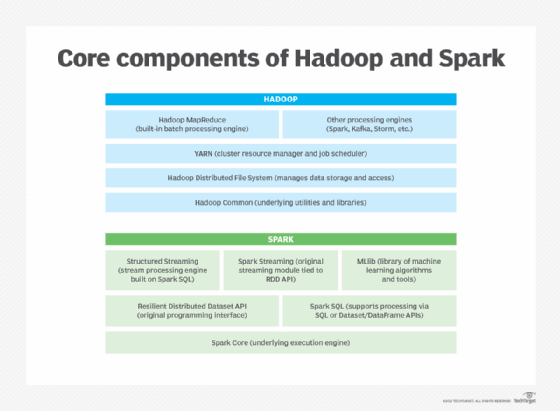
The main components of Hadoop include the following technologies:
- HDFS. Initially modeled on a file system developed by Google, HDFS manages the process of distributing, storing and accessing data across many separate servers. It can handle both structured and unstructured data, which makes it a suitable choice for building out a data lake.
- YARN. Short for Yet Another Resource Negotiator but typically referred to by its acronym, YARN is Hadoop's cluster resource manager, responsible for executing distributed workloads. It schedules processing jobs and allocates compute resources such as CPU and memory to applications. YARN took over those tasks from the Hadoop implementation of MapReduce when it was added as part of Hadoop 2.0 in 2013.
- Hadoop MapReduce. While its role was reduced by YARN, MapReduce is still the built-in processing engine used to run large-scale batch applications in many Hadoop clusters. It orchestrates the process of splitting large computations into smaller ones that can be spread out across different cluster nodes and then runs the various processing jobs.
- Hadoop Common. This is a set of underlying utilities and libraries used by Hadoop's other components.
What is Spark?
Spark was initially developed by Matei Zaharia in 2009, while he was a graduate student at the University of California, Berkeley. His main innovation with the technology was to improve how data is organized to scale in-memory processing across distributed cluster nodes more efficiently. Like Hadoop, Spark can process vast amounts of data by splitting up workloads on different nodes, but it typically does so much faster. This enables it to handle use cases that Hadoop can't with MapReduce, making Spark more of a general-purpose processing engine.
The following technologies are among Spark's key components:
- Spark Core. This is the underlying execution engine that provides job scheduling and coordinates basic I/O operations, using Spark's basic API.
- Spark SQL. The Spark SQL module enables users to do optimized processing of structured data by directly running SQL queries or using Spark's Dataset API to access the SQL execution engine.
- Spark Streaming and Structured Streaming. These modules add stream processing capabilities. Spark Streaming takes data from different streaming sources, including HDFS, Kafka and Kinesis, and divides it into micro-batches to represent a continuous stream. Structured Streaming is a newer approach built on Spark SQL that's designed to reduce latency and simplify programming.
- MLlib. A built-in machine learning library, MLlib includes a set of machine learning algorithms, plus tools for feature selection and building machine learning pipelines.
What are the key differences between Hadoop and Spark?
Hadoop's use of MapReduce is a notable distinction between the two frameworks. HDFS was tied to it in the first versions of Hadoop, while Spark was created specifically to replace MapReduce. Even though Hadoop no longer depends exclusively on MapReduce for data processing, there's still a strong association between them. "In the minds of many, Hadoop is synonymous with Hadoop MapReduce," said Erik Gfesser, director and chief architect at consulting firm Deloitte.
MapReduce in Hadoop has advantages when it comes to keeping costs down for large processing jobs that can tolerate some delays. Spark, on the other hand, has a clear advantage over MapReduce in delivering timely analytics insights because it's designed to process data mostly in memory.
Hadoop came first and revolutionized the way people thought about scaling data workloads. It made big data environments with large volumes and varying types of data feasible in organizations, particularly for aggregating and storing data sets to support analytics applications. Consequently, it's often adopted as a platform for data lakes that commonly store both raw data and prepared data sets for analytics uses.
While Hadoop can now be used for more than batch processing, it's primarily suited to analysis of historical data. Spark was designed from the ground up to optimize high-throughput data processing jobs. As a result, It's suitable for various uses. Spark is used in online applications and interactive data analysis, as well as extract, transform and load (ETL) operations and other batch processes. It can run by itself for data analysis or as part of a data processing pipeline.
Spark can also be used as a staging tier on top of a Hadoop cluster for ETL and exploratory data analysis. That highlights another key difference between the two frameworks: Spark's lack of a built-in file system like HDFS, which means it needs to be paired with Hadoop or other platforms for long-term data storage and management.
Now, here's a more detailed comparison of Hadoop and Spark in a variety of specific areas.
Architecture
The fundamental architectural difference between Hadoop and Spark relates to how data is organized for processing. In Hadoop, all the data is split into blocks that are replicated across the disk drives of the various servers in a cluster, with HDFS providing high levels of redundancy and fault tolerance. Hadoop applications can then be run as a single job or a directed acyclic graph (DAG) that contains multiple jobs.
In Hadoop 1.0, a centralized JobTracker service allocated MapReduce tasks across nodes that could run independently of each other, and a local TaskTracker service managed job execution by individual nodes. Starting in Hadoop 2.0, though, JobTracker and TaskTracker were replaced with these components of YARN:
- a ResourceManager daemon that functions as a global job scheduler and resource arbitrator;
- NodeManager, an agent that's installed on each cluster node to monitor resource usage;
- ApplicationMaster, a daemon created for each application that negotiates required resources from ResourceManager and works with NodeManagers to execute processing tasks; and
- resource containers that hold, in an abstract way, the system resources assigned to different nodes and applications.
In Spark, data is accessed from external storage repositories, which could be HDFS, a cloud object store like Amazon Simple Storage Service or various databases and other types of data stores. While most processing is done in memory, the platform can also "spill" data to disk storage and process it there when data sets are too large to fit into the available memory. Spark can run on clusters managed by YARN, Mesos and Kubernetes or in a standalone mode.
Similar to Hadoop, Spark's architecture has changed significantly from its original design. In early versions, Spark Core organized data into a resilient distributed dataset (RDD), an in-memory data store that is distributed across the various nodes in a cluster. It also created DAGs to help in scheduling jobs for efficient processing.
The RDD API is still supported. But starting with Spark 2.0, which was released in 2016, it was replaced as the recommended programming interface by the Dataset API. Like RDDs, Datasets are distributed collections of data with strong typing features, but they include richer optimizations through Spark SQL to help boost performance. The updated architecture also includes DataFrames, which are Datasets with named columns, making them similar in concept to relational database tables or data frames in R and Python applications. Structured Streaming and MLlib both utilize the Dataset/DataFrame approach.

Data processing capabilities
Hadoop and Spark are both distributed big data frameworks that can be used to process large volumes of data. Despite the expanded processing workloads enabled by YARN, Hadoop is still oriented mainly to MapReduce, which is well suited for long-running batch jobs that don't have strict service-level agreements.
Spark, on the other hand, can run batch workloads as an alternative to MapReduce and also provides higher-level APIs for several other processing use cases. In addition to the SQL, stream processing and machine learning modules, it includes a GraphX API for graph processing and SparkR and PySpark interfaces for the R and Python programming languages.
Performance
Hadoop processing with MapReduce tends to be slow and can be challenging to manage. Spark is often considerably faster for many kinds of batch processing: Proponents claim it can perform up to 100 times faster than an equivalent workload on Hadoop when processing batch jobs in memory, although the performance gain likely will be much lower in most real-world applications.
One big contributor to Spark's speed advantage is that it can do processing without having to write data back to disk storage as an interim step. But even Spark applications written to run on disk potentially can see 10 times faster performance than comparable MapReduce workloads on Hadoop, according to Spark's developers.
Hadoop may have an advantage, though, when it comes to managing many longer-running workloads on the same cluster simultaneously. Running a lot of Spark applications at the same time can sometimes create memory issues that slow the performance of all the applications.
Scalability
As a general principle, Hadoop systems can scale to accommodate larger data sets that are sporadically accessed because the data can be stored and processed more cost-effectively on disk drives versus memory. A YARN Federation feature added in Hadoop 3.0, which was released in 2017, enables clusters to support tens of thousands of nodes or more by connecting multiple "subclusters" that have their own resource managers.
The downside is that IT and big data teams may have to invest in more labor for on-premises implementations to provision new nodes and add them to a cluster. Also, with Hadoop, storage is colocated with compute resources on the cluster nodes, which can make it difficult for applications and users outside of the cluster to access the data. But some of these scalability issues can be automatically managed with Hadoop services in the cloud.
One of Spark's main advantages is that storage and compute are separated, which can make it easy for applications and users to access the data from anywhere. Spark includes tools that can help users dynamically scale nodes up and down depending on workload requirements; it's also easier to automatically reallocate nodes at the end of a processing cycle in Spark. A scaling challenge with Spark applications is ensuring that workloads are separated across nodes independent of each other to reduce memory leakage.
Security
Hadoop provides a higher level of security with less external overhead for long-term data retention. HDFS offers transparent, end-to-end data encryption with separate "encryption zone" directories and a built-in service for managing encryption keys; it also includes a permissions-based model to enforce access controls for files and directories, with the ability to create access control lists that can be used to implement role-based security and other types of rules for different users or groups.
In addition, Hadoop can operate in a secure mode with Kerberos authentication for all services and users. It can also take advantage of associated tools like Apache Knox, a REST API gateway that provides authentication and proxy services to enforce security policies in Hadoop clusters, and Apache Ranger, a centralized security management framework for Hadoop environments. This combination of features provides a stronger security starting point compared to Spark.
Spark has a more complex security model that supports different levels of security for different types of deployments. For example, it uses a shared-secret authentication approach for remote procedure calls between Spark processes, with deployment-specific mechanisms to generate the secret passwords. In some cases, security protections are limited because all applications and daemons share the same secret, although that doesn't apply when Spark runs on YARN or Kubernetes.
The Spark model was primarily built to enforce security on top of data streams, which are less permanent than data stored for long periods. One concern is that this could open up Spark data infrastructures to a broader scope and scale of cybersecurity attacks. In addition, authentication and other security measures aren't enabled by default in Spark. That said, sufficient protections can be achieved by combining the appropriate encryption architecture with proper key management policies.
Applications and use cases
Both Hadoop MapReduce and Spark are often used for batch processing jobs, such as ETL tasks to move data into a data lake or data warehouse. They both can also handle various big data analytics applications involving recent or historical data, such as customer analytics, predictive modeling, business forecasting, risk management and cyber threat intelligence.
Spark is often a better choice for data streaming and real-time analytics use cases, such as fraud detection, predictive maintenance, stock trading, recommendation engines, targeted advertising and airfare and hotel pricing. It's also typically a better fit for ongoing data science initiatives, including graph computations and machine learning applications.
Machine learning
Looking at machine learning specifically, Hadoop is best suited as a staging tier for managing the extremely large data sets that applications often involve. It's good at ingesting raw data from various sources and storing the results of ETL processes for subsequent exploration and analysis by machine learning algorithms.
In contrast, Spark is better for direct exploratory data analysis and deployment of machine learning models. Its MLlib module includes algorithms optimized for various types of machine learning processes, such as classification, regression, clustering and pattern mining; the module also provides tools for feature engineering, pipeline development and model evaluation, plus linear algebra and statistics utilities. In addition, Spark is now the recommended back-end platform for Apache Mahout, a machine learning and distributed linear algebra framework that initially was built on top of Hadoop MapReduce.
However, Hadoop and Spark can be used together to support machine learning. For example, data scientists and data engineers may pull raw data from HDFS into Spark for interactive exploration and data wrangling; after the feature engineering and selection process is completed, the machine learning models will also directly aggregate and process data in Spark. Features that are interesting but not relevant for a specific project could be archived in a Hadoop cluster for potential future use.
Deployment and processing costs
Organizations can deploy both the Hadoop and Spark frameworks using the free open source versions or commercial cloud services and on-premises offerings. However, the initial deployment costs are just one component of the overall cost of running the big data platforms. IT and data management teams also must include the resources and expertise required to securely provision, maintain and update the underlying infrastructure and big data architecture.
One difference is that a Spark implementation typically will require more memory, which can increase costs when building out a cluster. Hadoop can also be a more cost-effective platform for running occasional reports on commodity hardware, and it can help keep costs down when organizations want to retain large volumes of data for future analytics projects.
The broad Hadoop ecosystem includes a variety of optional supporting technologies to install, configure and maintain, including widely used tools like the HBase database and Hive data warehouse software. Many of them can be used with Spark, too. Commercial versions of the frameworks bundle sets of these components together, which can simplify deployments and may help keep overall costs down.
How to choose between Hadoop and Spark
Besides being more cost-effective for some applications, Hadoop has better long-term data management capabilities than Spark. That makes it a more logical choice for gathering, processing and storing large data sets, including ones that may not serve current analytics needs. Spark is more adept at supporting analytics applications that run in interactive mode and ones in which multiple operations need to be performed simultaneously or chained together.
But, as mentioned above, Hadoop and Spark aren't mutually exclusive. Most organizations that use Hadoop for data engineering, data preparation and analytics applications also use Spark as part of those workflows without any issues, said Sushant Rao, senior director of product marketing for analytics, transactional applications and cloud at big data platform vendor Cloudera. In addition, both frameworks are commonly combined with other open source components for various tasks.
While more than a half-dozen vendors initially created commercial Hadoop distributions, the market has consolidated considerably. Cloudera remains as an independent vendor -- it acquired Hortonworks, a rival Hadoop pioneer, in 2019 and now offers a combined Cloudera Data Platform technology bundle that was designed to be cloud-native. In addition, cloud platform market leaders AWS, Microsoft and Google all offer cloud-based big data platforms and managed services with Hadoop, Spark and other big data technologies -- Amazon EMR, Azure HDInsight and Google Cloud Dataproc, respectively.
In a sign of the diminishing focus on MapReduce, though, AWS and Google have deemphasized Hadoop in their marketing materials and now highlight Spark and some of the other technologies from the Hadoop ecosystem. Databricks, a vendor founded by Spark creator Matei Zaharia and others involved in that framework's early development, also offers a cloud-based data processing and analytics platform built on Spark, now known as the Databricks Lakehouse Platform.







