Executing SQL statements using prepared statements and statement pooling
In this database tutorial, find out about executing SQL statements using prepared statements and statement pooling. Learn what a statement pool is and how to retrieve long data types efficiently.
 |
In this excerpt from The Data Access Handbook you'll learn strategic methods for creating a high-performing database architecture. This section features information about executing SQL statements using prepared statements and statement pooling. Get tips for accessing data via queries and discover how to retrieve long data.
Table of Contents
![]() Designing for performance: Strategic database application deployments
Designing for performance: Strategic database application deployments
![]() An introduction to database transaction management
An introduction to database transaction management
![]() Executing SQL statements using prepared statements and statement pooling
Executing SQL statements using prepared statements and statement pooling
![]() Database access security: network authentication or data encryption?
Database access security: network authentication or data encryption?
![]() Static SQL vs. dynamic SQL for database application performance
Static SQL vs. dynamic SQL for database application performance

SQL Statements
Will your application have a defined set of SQL statements that are executed multiple times? If your answer is yes, you will most likely want to use prepared statements and statement pooling if your environment supports it.
Using Statements Versus Prepared Statements
A prepared statement is a SQL statement that has been compiled, or prepared, into an access or query plan for efficiency. A prepared statement is available for reuse by the application without the overhead in the database of re-creating the query plan. A prepared statement is associated with one connection and is available until it is explicitly closed or the owning connection is closed.
Most applications have a set of SQL statements that are executed multiple times and a few SQL statements that are executed only once or twice during the life of an application. Although the overhead for the initial execution of a prepared statement is high, the advantage is realized with subsequent executions of the SQL statement. To understand why, let's examine how a database processes a SQL statement.
The following occurs when a database receives a SQL statement:
- The database parses the statement and looks for syntax errors.
- The database validates the user to make sure the user has privileges to execute the statement.
- The database validates the semantics of the statement.
- The database figures out the most efficient way to execute the statement and prepares a query plan. Once the query plan is created, the database can execute the statement.
When a prepared query is sent to the database, the database saves the query plan until the driver closes it. This allows the query to be executed time and time again without repeating the steps described previously. For example, if you send the following SQL statement to the database as a prepared statement, the database saves the query plan:
SELECT * FROM Employees WHERE SSID = ?
Note that this SQL statement uses a parameter marker, which allows the value in the WHERE clause to change for each execution of the statement. Do not use a literal in a prepared statement unless the statement will be executed with the same value(s) every time. This scenario would be rare.
Using a prepared statement typically results in at least two network round trips to the database server:
- One network round trip to parse and optimize the query
- One or more network round trips to execute the query and retrieve the results
Note that not all database systems support prepared statements; Oracle, DB2, and MySQL do, and Sybase and Microsoft SQL Server do not. If your application sends prepared statements to either Sybase or Microsoft SQL Server, these database systems create stored procedures. Therefore, the performance of using prepared statements with these two database systems is slower.
Some database systems, such as Oracle and DB2, let you perform a prepare and execute together. This functionality provides two benefits. First, it eliminates a round trip to the database server. Second, when designing your application, you don't need to know whether you plan to execute the statement again, which allows you to optimize the next execution of the statement automatically.
Read the next section about statement pooling to see how prepared statements and statement pooling go hand in hand.
Statement Pooling
If you have an application that repeatedly executes the same SQL statements, statement pooling can improve performance because it prevents the overhead of repeatedly parsing and creating cursors (server-side resource to manage the SQL request) for the same statement, along with the associated network round trips.
A statement pool is a group of prepared statements that an application can reuse. Statement pooling is not a feature of a database system; it is a feature of database drivers and application servers. A statement pool is owned by a physical connection, and prepared statements are placed in the pool after their initial execution. For details about statement pooling, see Chapter 8, "Connection Pooling and Statement Pooling."
How does using statement pooling affect whether you use a statement or a prepared statement?
- If you are using statement pooling and a SQL statement will only be executed once, use a statement, which is not placed in the statement pool. This avoids the overhead associated with finding that statement in the pool.
- If a SQL statement will be executed infrequently but may be executed multiple times during the life of a statement pool, use a prepared statement. Under similar circumstances without statement pooling, use a statement. For example, if you have some statements that are executed every 30 minutes or so (infrequently), the statement pool is configured for a maximum of 200 statements, and the pool never gets full, use a prepared statement.
Data Retrieval
To retrieve data efficiently, do the following:
- Return only the data you need. Read "Retrieving Long Data," page 31.
- Choose the most efficient way to return the data. Read "Limiting the Amount of Data Returned," page 34, and "Choosing the Right Data Type," page 34.
- Avoid scrolling through the data. Read "Using Scrollable Cursors," page 36.
- Tune your database middleware to reduce the amount of information that is communicated between the database driver and the database. Read "The Network," page 44.
For specific API code examples, read the chapter for the standards-based API that you work with:
- For ODBC users, see Chapter 5.
- For JDBC users, see Chapter 6.
- For ADO.NET users, see Chapter 7.
Understanding When the Driver Retrieves Data
You might think that if your application executes a query and then fetches one row of the results, the database driver only retrieves that one row. However, in most cases, that is not true; the driver retrieves many rows of data (a block of data) but returns only one row to the application. This is why the first fetch your application performs may take longer than subsequent fetches. Subsequent fetches are faster because they do not require network round trips; the rows of data are already in memory on the client.
Some database drivers allow you to configure connection options that specify how much data to retrieve at a time. Retrieving more data at one time increases throughput by reducing the number of times the driver fetches data across the network when retrieving multiple rows. Retrieving less data at one time increases response time, because there is less of a delay waiting for the server to transmit data. For example, if your application normally fetches 200 rows, it is more efficient for the driver to fetch 200 rows at one time over the network than to fetch 50 rows at a time during four round trips over the network.
Retrieving Long Data
Retrieving long data—such as large XML data, long varchar/text, long varbinary, Clobs, and Blobs— across a network is slow and resource intensive. Do your application users really need to have the long data available to them? If yes, carefully think about the most optimal design. For example, consider the user interface of an employee directory application that allows the user to look up an employee's phone extension and department, and optionally, view an employee's photograph by clicking the name of the employee.
| Employee | Phone | Dept |
| Harding | X4568 | Manager |
| Hoover | X4324 | Sales |
| Lincoln | X4329 | Tech |
| Taft | X4569 | Sales |
Returning each employee's photograph would slow performance unnecessarily just to look up the phone extension. If users do want to see the photograph, they can click on the employee's name and the application can query the database again, specifying only the long columns in the Select list. This method allows users to return result sets without having to pay a high performance penalty for network traffic.
Having said this, many applications are designed to send a query such as SELECT * FROM employees and then request only the three columns they want to see. In this case, the driver must still retrieve all the data across the network, including the employee photographs, even though the application never requests the photograph data.
Some database systems have optimized the expensive interaction between the database middleware and the database server when retrieving long data by providing an optimized database data type called LOBs (CLOB, BLOB, and so on). If your database system supports these data types and long data is created using those types, then the processing of queries such as SELECT * FROM employees is less expensive. Here's why. When a result row is retrieved, the driver retrieves only a placeholder for the long data (LOB) value. That placeholder is usually the size of an integer—very small. The actual long data (picture, document, scanned image, and so on) is retrieved only when the application specifically retrieves the value of the result column.
For example, if an employees table was created with the columns FirstName, LastName, EmpId, Picture, OfficeLocation, and PhoneNumber, and the Picture column is a long varbinary type, the following interaction would occur between the application, the driver, and the database server:
- Execute a statement—The application sends a SQL statement (for example, SELECT * FROM table WHERE ...) to the database server via the driver.
- Fetch rows—The driver retrieves all the values of all the result columns from the database server because the driver doesn't know which values the application will request. All values must be available when needed, which means that the entire image of the employee must be retrieved from the database server regardless of whether the application eventually processes it.
- Retrieve result values into the application—When the application requests data, it is moved from the driver into the application buffers on a column-by-column basis. Even if result columns were prebound by the application, the application can still request result columns ad hoc.
Now suppose the employees table is created with the same columns except that the Picture field is a BLOB type. Now the following interaction would occur between the application, the driver, and the database server:
- Execute a statement—The application sends a SQL statement (for example, SELECT * FROM table WHERE ...) to the database server via the driver.
- Fetch rows—The driver retrieves all the values of all the result columns from the database server, as it did in the previous example. However, in this case, the entire employee image is not retrieved from the database server; instead, a placeholder integer value is retrieved.
- Retrieve result values into the application—When the application requests data, it is moved from the driver into the application buffers on a column-by-column basis. If the application requests the contents of the Picture column, the driver initiates a request to the database server to retrieve the image of the employee that is identified by the placeholder value it retrieved. In this scenario, the performance hit associated with retrieving the image is deferred until the application actually requests that data.
In general, LOB data types are useful and preferred because they allow efficient use of long data on an as-needed basis. When the intent is to process large amounts of long data, using LOBs results in extra round trips between the driver and the database server. For example, in the previous example, the driver had to initiate an extra request to retrieve the LOB value when it was requested. These extra round trips usually are somewhat insignificant in the overall performance of the application because the number of overall round trips needed between the driver and the database server to return the entire contents of the long data is the expensive part of the execution.
Although you might prefer to use LOB types, doing so is not always possible because much of the data used in an enterprise today was not created yesterday. The majority of data you process was created long before LOB types existed, so the schema of the tables you use may not include LOB types even if they are supported by the version of the database system you are using. The coding techniques presented in this section are preferred regardless of the data types defined in the schema of your tables.
Limiting the Amount of Data Returned
One of the easiest ways to improve performance is to limit the amount of network traffic between the database driver and the database server—one way is to write SQL queries that instruct the driver to retrieve from the database and return to the application only the data that the application requires. However, some applications need to use SQL queries that generate a lot of traffic. For example, consider an application that needs to display information from support case histories, which each contain a 10MB log file. But, does the user really need to see the entire contents of the file? If not, performance would improve if the application displayed only the first 1MB of the log file.
Choosing the Right Data Type
Advances in processor technology have brought significant improvements to the way that operations, such as floating-point math, are handled. However, when the active portion of your application does not fit into on-chip cache, retrieving and returning certain data types is expensive. When you are working with data on a large scale, select the data type that can be processed most efficiently. Retrieving and returning certain data types across the network can increase or decrease network traffic. Table 2-1 lists the fastest to the slowest data types to process and explains why.
Table 2-1 Fastest to Slowest Processing of Data Types
| Data Type | Processing |
| binary | Transfer of raw bytes from database to application buffers. |
| int, smallint, float | Transfer of fixed formats from database to application buffers. |
| decimal | Transfer of proprietary data from database to database driver. Driver must decode, which uses CPU, and then typically has to convert to a string. (Note: All Oracle numeric types are actually decimals.) |
| timestamp | Transfer of proprietary data from database to database driver. Driver must decode, which uses CPU, and then typically has to convert to a multipart structure or to a string. The difference between timestamp processing and decimal is that this conversion requires conversion into multiple parts (year,month, day, second, and so on). |
| char | Typically, transfer of larger amounts of data that must be converted from one code page to another, which is CPU intensive, not because of the difficulty, but because of the amount of data that must be converted. |
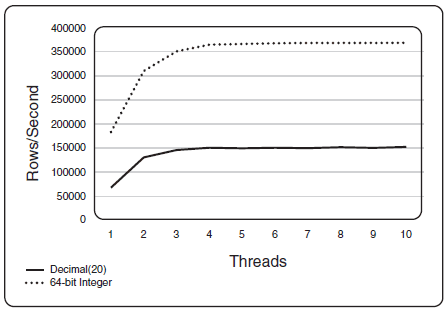
Figure 2-8 shows a comparison of how many rows per second are returned when a column is defined as a 64-bit integer data type versus a decimal(20) data type. The same values are returned in each case. As you can see in this figure, many more rows per second are returned when the data is returned as an integer.
Figure 2-8 Comparison of different data types
Using Scrollable Cursors
Scrollable cursors allow an application to go both forward and backward through a result set. However, because of limited support for server-side scrollable cursors in many database systems, drivers often emulate scrollable cursors, storing rows from a scrollable result set in a cache on the machine where the driver resides (client or application server). Table 2-2 lists five major database systems and explains their support of server-side scrollable cursors.
Table 2-2 Database Systems Support of Server-Side Scrollable Cursors
| Database System | Explanation |
| Oracle | No native support of database server-side scrollable cursors. Drivers expose scrollable cursors to applications by emulating the functionality on the client. |
| MySQL | No native support of database server-side scrollable cursors. Drivers expose scrollable cursors to applications by emulating the functionality on the client. |
| Microsoft SQL Server | Server-side scrollable cursors are supported through stored procedures. Most drivers expose server-side cursors to applications. |
| DB2 | Native support of some server-side scrollable cursor models. Some drivers support server-side scrollable cursors for the most recent DB2 versions. However, most drivers expose scrollable cursors to applications by emulating the functionality on the client. |
| Sybase ASE | Native support for server-side scrollable cursors was introduced in Sybase ASE 15.Versions prior to 15 do not natively support serverside scrollable cursors. Drivers expose scrollable cursors to applications by emulating the functionality on the client. |
One application design flaw that we have seen many times is that an application uses a scrollable cursor to determine how many rows a result set contains even if server-side scrollable cursors are not supported in the database system. Here is an ODBC example; the same concept holds true for JDBC.Unless you are certain that the database natively supports using a scrollable result set, do not call SQLExtendedFetch() to find out how many rows the result set contains. For drivers that emulate scrollable cursors, calling SQLExtendedFetch() results in the driver returning all results across the network to reach the last row.
This emulated model of scrollable cursors provides flexibility for the developer but comes with a performance penalty until the client cache of rows is fully populated. Instead of using a scrollable cursor to determine the number of rows, count the rows by iterating through the result set or get the number of rows by submitting a Select statement with the Count function. For example:
SELECT COUNT(*) FROM employees WHERE ...
More on accessing data:
- Read the next section — Database access security: network authentication or data encryption?
- Intrigued by this book excerpt? Download a free PDF of this chapter: Chapter 2 —Designing for Performance: What's Your Strategy?
- Read more excerpts and download more sample chapters from our Data Management bookshelf
- To purchase the book or similar titles, visit InformIT







