schema
What is a schema?
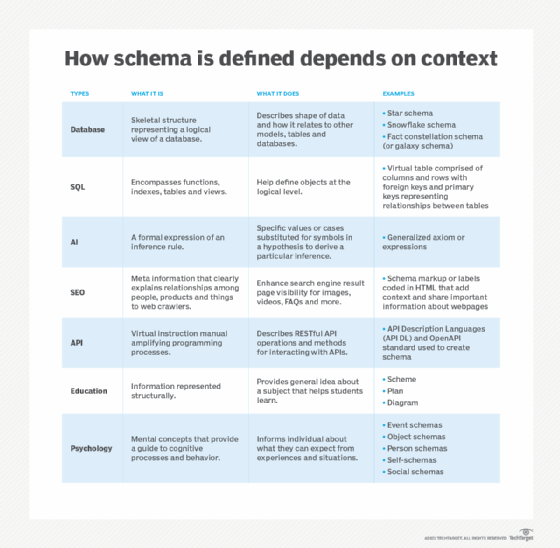
In computer programming, a schema (pronounced SKEE-mah) is the organization or structure for a database, while in artificial intelligence (AI), a schema is a formal expression of an inference rule.
The word schema originates from the Greek word for "form or figure." The concept appears in both database management and AI. In general, a schema is a graphical representation that makes it easy to organize information or knowledge.
In databases, a schema acts as a blueprint that visually represents how data is -- or will be -- organized within a database. Also, the activity of data modeling in a database leads to the creation of a schema.
In AI, a schema is derived from mathematics and is essentially a generalized axiom or expression where specific values or cases are substituted for symbols in a hypothesis to derive a particular inference. It represents how information will be organized in a structured format and can be used in multiple AI contexts, including natural language understanding, machine learning and knowledge representation.
There are different types of schemas, and their meanings are closely related to fields such as data science, education, marketing, search engine optimization (SEO) and psychology. Even so, how a schema is defined depends on the context.
What is a database schema?
A database schema is like a skeletal structure representing a logical view of the entire database. It describes the shape of the data and how it relates to other models, tables and databases, and devises all the constraints applied to that data. The idea of a schema is used in both relational databases and object-oriented databases.
Types of database schemas
Database schemas can be broadly divided into three categories:
- Physical database schemas that provide technical, contextual and syntactical information to help define how the datalike files are stored in the database.
- Logical database schemas that define schema objects and describe all the logical constraints, including integrity, tables and views, and rules applied on the stored data.
- Conceptual database schemas that show how the database will be organized and which business rules are involved.
Examples of database schema designs
Database schema diagrams show the relationships between database tables. Many types of schema designs are available. The following are three common designs:
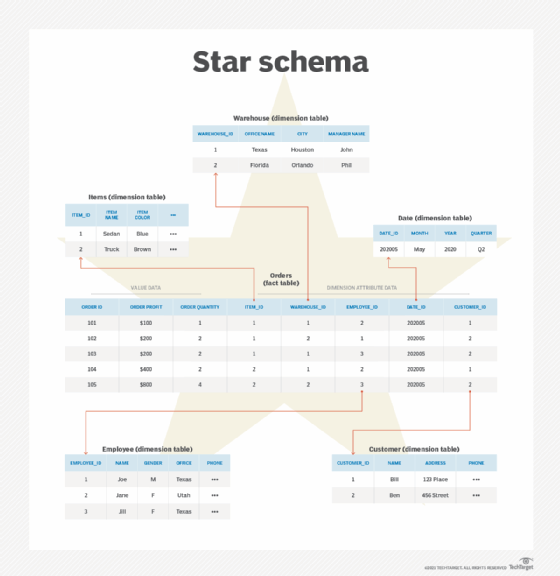
Star schema
The star schema is a simple schema that's often used to build data warehouses for business intelligence or analytics applications. It includes a fact table and one or more dimensional tables. Specifically, the fact table stores the main data points and is surrounded by the dimensional table or tables. It denormalizes data to speed up and simplify querying.
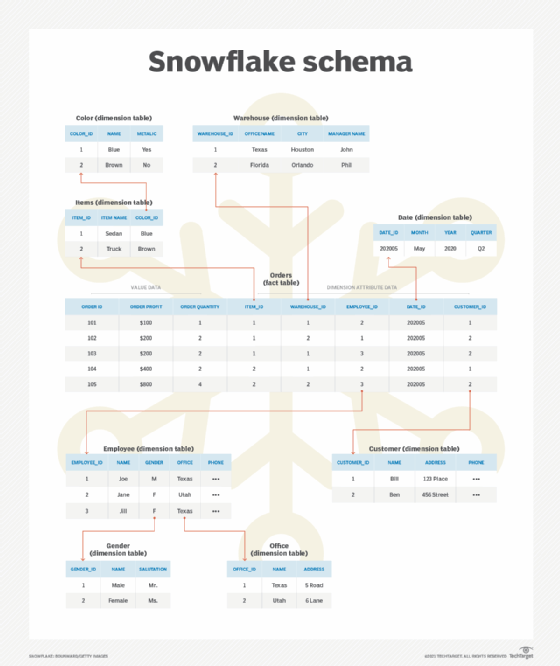
Snowflake schema
A snowflake schema is a more complex adaptation of a star schema. It also includes a central fact table surrounded by dimensional tables. The latter are fully normalized, which can save on storage space and minimize data redundancy. Also, the dimensional tables can have their own dimensional tables, known as lookup tables, that are also normalized to remove redundancy and prevent the repetition of values. Both star and snowflake schemas are used in relational database management systems.
Fact constellation or galaxy schema
A fact constellation schema, also known as a galaxy schema, is also used in data warehouses. It is more complex than the star and snowflake schemas. It uses multiple fact tables that share several normalized dimension tables. As with the snowflake schema, normalization in the galaxy schema prevents data redundancy or inconsistency.
Other popular schema designs include the following:
- Flat model.
- Network model.
- Hierarchical model.
- Relational model.
What is a schema in SQL?
A Structured Query Language (SQL) database encompasses functions, indexes, tables and views. There are no restrictions to the number of objects that can be stored within a database. A schema is an essential element of a SQL database. It lists and defines the database objects at the logical level. Security permissions and user privileges can be assigned to a SQL schema to control user access and secure the database objects. The schema owner is one of the database's users.
A view in SQL is a virtual table comprised of columns and rows based on the result set of a statement. Foreign keys and primary keys represent the relationships between one table and another.
What is a schema in SEO?
In SEO, schemas and schema markups -- a form of microdata -- play a critical role in defining the different entities on a website and explaining the relationships among people, products and things to web crawlers, also known as spiders. By providing this extra content, sites can help search crawlers successfully match search intent with content. Schemas define the asset type that web crawlers can quickly crawl through without any added visibility or extra context that often leads to latency. This approach also helps enhance search engine results page (SERP) visibility for images, videos, FAQs and more.
Also, adding a schema markup to a webpage creates an enhanced description -- also known as a rich snippet -- that will then appear on the SERP. The markup labels are coded in Hypertext Markup Language to add context and share important information about website pages with the search engine's spiders.
What is an API schema?
The creation of application programming interface description languages first enabled API schemas, which later led to today's OpenAPI standard. API schemas bring guides, connectors or descriptors to various aspects of application development. Readable by both humans and machines, an API schema describes RESTful API operations and methods for interacting with APIs. It is like a virtual instruction manual that makes APIs easier to use and more discoverable. When well executed, an API schema also enables the creation of software development kits and machine-generated API documentation.
Since API schemas are so useful, many developers have adopted the idea of schema-first API design. The idea is to first write the API definition in an API specification language, and only then write the code.
Additional kinds of schemas
Other types of schemas include the following:
Education
In education, a schema is generally a scheme, plan or diagram about something that can help students learn.
Psychology
In psychology and other social sciences, a schema describes a mental concept. It enables an individual to understand what to expect from diverse experiences and circumstances. These schemas are developed and based on life experiences and act as a guide to one's cognitive processes and behavior.
In psychology, there are several types of schemas, including the following:
- Event schemas.
- Object schemas.
- Person schemas.
- Self-schemas.
- Social schemas.
Social sciences also use the word schema to categorize events and objects based on common characteristics and elements that help interpret and predict the world.
Explore the differences between dimension tables vs. fact tables and delve deeper into the differences between a star schema and a snowflake schema. Learn more about API schemas, their history and how one API-centric application development cloud company puts them to good effect.




